Notations
| Tags |
|---|
Notation stuff
When dealing with random variables, we typically need to say something like , but we just use a shorthand at times . It’s the same thing.
We use the term to get the values that the RV can take on.
More sophisticated notation
Sometime we use the notation if using another is confusing. This is common for CDF, or if the likelihood is a random varaible
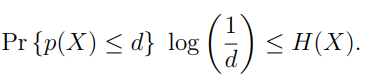
- we use CAPITAL to represent the random variable itself. So means a random variable such that we run it through the probability function after sampling
- general rule of thumb: if it’s outside of a summation, and you just want to refer to “something”, capital is the way to go.
- we use lowercase to represent a sample or an instance. So is a number (shows up in summations, etc).
Distributions vs. probabilities 🐧
A distribution has no "p" attached to it. For example, . In this case, is a distribution. However, is a probability. You can find the probability by plugging in into the CDF formula defined by .
Prior and Posterior
The prior is what you believe before some observation. For example, . The posterior is what you believe after some observation, like
Densities
Here’s also a point of confusion that sounds stupid but it happens all the time. The is not a specific function. So isn’t the same as , etc. This is true even when the is specialized for some application. Probability is not a function.
The density means the likelihood of , which ALSO means that if you were to select at random, the likelihood of being this current has likelihood .
Remember that is a value, as is scalar. Therefore, is well-defined, but NOT . The conditioning must always be deterministic. On the other hand, is totally fine; it’s just another random variable.