Change of Variable
| Tags | Aside |
|---|
Mapping between distributions / functions
This is a classic problem and it’s very tricky to understand. Here’s the setup: you have some known , some invertible mapping function , and you want to find as a function of .
Non-distribution setup
Without the question of distribution, this is actually really simple.
You take your and you map it into the domain that works for . No biggie.
Distribution-based setup
Why doesn’t this work if is a density function? It has to do with density. Imagine the were rubber bands. if you have to stretch or shrink the rubber band in your mapping of , then you run into the problem of having the same density with different scales, leading to a change in the integral.
More formally, if , we’ve got a problem that we can solve with standard change of variable techniques. In calculus, we implemented these techniques when we mapped between two domains (u-substitution) but we wanted to keep the integral equivalent.
- Start with
- Find
- Compute in terms of , getting you the final answer
From this, we can derive a general rule (using the derivative of the inverse function general form):
Proof (from first principles)
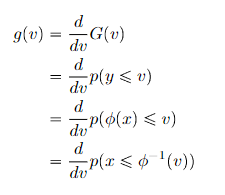
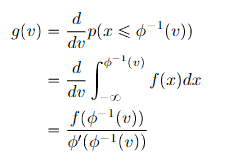
Generalization to vector-distributions
For vector distributions, we are dealing with a multi-variable transformation. This transformation, like the one-dimensional case, must be invertible. For a matrix, it must be full-rank.
Here, instead of worrying about vs , we are worried about mapping onto , where is some unit element. As we’ve learned in multivariate calculus, the convenient notion is the Jacobian determinant, i.e.
Note how the forms are super similar; we just replace the derivative with the determinant of the jacobian. Recall that the jacobian describes how the unit-area stretches or shrinks with the transformation, so this is intuitive. So you’re almost “paying tax” by “unshrinking” from to before you apply the function.
Intuition
Let’s jump directly to the higher dimension.
- we know represents how much the space stretches as we apply the transformation from .
- is the density in X-space. If the Y→X increases, everything is naturally divided by as we go into X-land. Therefore, to reverse this process, we multiply the value by
- If Y→X decreases, the same logic applies, just with a that is less than 1
You can think of a transformation as naturally dividing by the “stretch” factor , and you need to compensate as you map it back.
Worked example
If we have known and we have a good function , then we can compute . Often, we get at the start, which is fine. So, you just scale your values by . If the operation is linear, this is a constant
- rule of thumb: if is a tighter domain, expect to be smaller. If is a looser domain, expect to be larger.