Concentration Inequalities ⭐
| Tags |
|---|
Convergence of Random Variables
What is a sequence of random variables? Well, maybe think about dice that come out from a dice factory. Each dice is an RV, and there may be a pattern in how the dice behave.
There are different notions of convergence.
in distributionmeans that we converge to the same sufficient statistics
in probabilitymeans that for every , we have . Intuitively, the probability of an “unusual” outcome becomes more rare as sequence progresses. Close to the idea of a hoeffding’s inequality, useful for the law of large numbers, etc.- with this inequaltiy, you can say that we asymptotically bound this property within an epsilon ball
- Formally: for every , there exists some such that for all , we have . Note how this depends on both the delta and the epsilon.
in mean squareif as .
with probability 1(almost surely) if .- this is different from 2) because we take the limit inside the probability.
Notation-wise, we use for distribution, for probability, etc.
Understanding what convergence means
Distributional convergence makes sense. But how can the other types of convergence happen if these are random variables? Well, there are two common cases:
- The DIRECTLY, and as . In other words, there’s some sort of coupling between the RV’s.
- The is a constant. Here, we get some standard things like the central limit theorem, where (overload of notation), and is the mean of the current samples.
Ways of convergence, constraint (another way of looking at this)
Asymptotic bounds: this guarantees that some as . You might get a high probability bound of , which gives a bit more structure asympotically
- Example: law of large numbers (loose)
- Pros: often the most intuitive, easy to work with
- Cons: may not say too much about low
High probability bounds: this guarantees that chance is . you get an interplay between . You can set two of them and the third one will be derived. Usually is written as a function of , but you can easily invert
- Example: all tail bounds, hoeffding’s inequality
- Pros: strict definition, works on every
General Tail Bounds
Tail bounds are important because they limit how large your tail is in a distribution, which naturally has implications for learning algorithms that could potentially exclude the tail of a distribution
Markov’s Inequality
We can show that for any non-negative random variable and , we have
Intuitively, as we get further away from the expected value, the likelihood decreases. This is mathematically super helpful as it relates probabilities to expectations, and we will use it to build up law of large numbers.
Proof (integral definition of probability and expectation)

Chebyshev’s Inequality
We can show very easily that
where is the variance and mean of , respectively. This brings us closer to the idea of hoeffding’s inequaltiy and the law of large numbers.
Proof (Markov’s inequality)
Let

Upshot: to show the law of large numbers for any stochastic process, it is sufficient to show that the variance of the sample goes to zero.
General Tail Bound
Claim: if is real, then for any ,
Proof (expansion into integrals)

Gaussian tail bound
Claim: if is gaussian with mean 0 and variance 1, then
Proof (general tail bound + moment generating function)

and then let , getting us
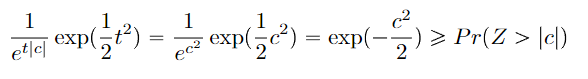
If you want this to work with non-unitary variance, just plug in the non-unitary variance MGF of the gaussian and set .
This gets us a stronger variant of Chebyshev’s inequality, and it is food for thought.
Hoeffding’s inequality ⭐
Hoeffding’s inequality in the general form is as follows: given and , we have
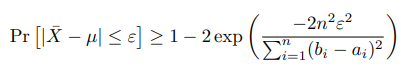
We often find a looser bound by replacing term with , because the range is always less than the variance.
Common forms include
- if you are bounded in
- if you are bounded in [0,1] and you are dealing with SUMS, not averages.
Proof (lots of algebra + Markov’s inequality)
Start with . If , then for every . Markov’s inequality therefore states that
After expanding back into , you get that this is equal to .
With Taylor expansion, you get that . We know that , which means that .
The minimizer of is just . Plugging this back in, we get
Now, this isn’t the true inequality. We got a weaker result with the instead of . This is a minor technicality and we can strenthen with better argument, but this is the general idea.
Uses of Hoeffding’s inequality
Anytime you see some sample sum or mean, you can use Hoeffding’s inequality to establish some bounds on how far we stray from the mean
Lemma: Sample variances
The variance of is
Proof (from definitions)

McDiarmid’s Inequality
This states that for any IID random variables and any function that has bounded differences (i.e. substituting the ith coordinate changes by at most a finite . Then…
As usual, the alternate (average) form is
Now, if is the summation, we get Hoeffding’s inequality.
The proof comes from Martingales, and so we will omit it here. Just know that this is a powerful inequality that bounds samples to an expectation.
CLT (Central Limit Theorem)
The CLT leverages the law of large numbers to make the claim that all RV averages are gaussian in nature.
If are IID random variables from distribution that has covariance . Let , then
- (this is the weak law of large numbers)
-
- If you were to move this around, you’d get which makes sense. You’re narrowing around the mean, which is a result of the law of large numbers
The CLT is derivable from Hoeffding’s inequality
Delta Method
Using point (2), we can apply the Delta Method and assert that for any non-zero derivative function , we have

This is a very helpful extension of the CLT.
Law of large numbers
The laws of large numbers can be derived from Hoeffding’s inequality: we see that the sample mean gets closer to the true mean.
The actual Law ⭐
Both the weak and strong forms of the law of large numbers state that the average of samples (denoted by ) converges to .
The weak form states that the convergence happens in probability. Formally, this means that
Proof (Markov’s inequality and sample variances)
Let

which gets us
and as we can see, the limit of the RHS pinches to 0, and that is what we wanted to show.
The strong form states that it happens almost surely. Proof is omitted for now.