Conditional Models
| Tags | CS 228Inference |
|---|
Conditional Models motivation
When you have a PGM, you often want to do something with it that involves observing something and then using that observation to create something else

In previous classes we talked about generative vs discriminative models, and now we can formalize it. These two models are technically I-equivalent, so they do encode the same independencies. However, they each have their own benefits and drawbacks
Generative models
In the generative model, the influences the observed . Because it is generative, you necessarily need the entire joint distribution. So you need and all forms of . Eventually, you will get . From this, you can make all sorts of inferences. For example, if you divide by you can get .

The pro, again, is that we have the joint distribution at hand.
The massive con is that the joint distribution can be horribly complicated (think about how we would represent in the above graph!
To simplify, we often make additional independence assumptions. For example, in Naive Bayes, we assume that every , which removes the densely connected children edges.

You would calculate the conditional probability in a Naive Bayes setup like
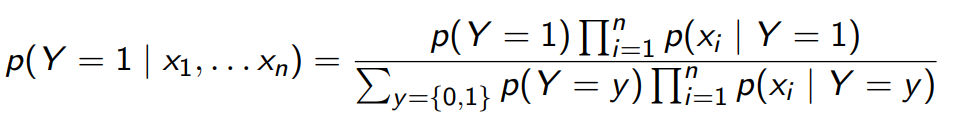
Discriminative Models
Ok, so why don’t we try something different this time? What if we drew arrows in the other direction?

In this case, there are a crap ton of variables influencing , so we can’t make a tabular look-up that we would have done for the naive bayes. Instead, we make this assumption:
where is a valid probability. In other words, we can represent the dependencies as a function. hmmmm. This should sound rather like regression!
In fact, we can try the following:
This is just logistic regression.
What are we assuming?
It seems like we just got free lunch. In Naive Bayes, we were only able to make a tractable conditional inference when we made the conditional independence assumption. Why is it easier here?
Well, there’s one crucial thing missing. Because the was directly accessible from the model (without using Bayes rule), we had no need to calculate . Without , we don’t have the joint distribution.
Therefore, the generative models can do many things because it is a joint distribution, while the discriminative model is relegated to calculating . So in not giving up the dependencies between variables, we had to give up the joint distribution.
The assumptions also come with the choice of . For example, in the logistic regression above, we are assuming implicitly that the data is linearly separable.

When discriminative and generative intersect
It can actually be shown that if in an IID fashion and , through bayes rule we arrive at the fact that is in logistic form. We did this in 229.
So this reinforces the no free lunch idea. The predictive power of these two models are equivalent.
Compare and contrast
Discrimination cons
What if we are given partial observability of the ? With the generative model, it is fine as we can marginalize across the unknown values to give our best guess. However, the discriminative models are dead in the water because the key assumption is that it observes all of the necessary variables.
What’s more, because discriminative models are typically trained through gradient-based methods, it often needs more data.
Discrimination pros
The key power of discrimination is that it doesn’t make any assumptions about . Sometimes two features are very closely correlated (think “bank” and “account” in an email). Therefore, the conditional independence assumption may not be correct and we can underfit.
On the other hand, if the discriminative model sees two correlated features, it will learn to ignore one of those features. Or, at least it is capable of learning this ignoring, while the generative models can’t.
Conditional random fields
Previously, we looked at models where was a single value and as a set. Can we make things larger now with ? What if we had many and many ?
A good example is below

we want to predict letters given a series of images.
This is still a discriminative model because we don’t want to find the distribution . We just want to find and maximize the to make a prediction.
Intuition
This is a weird thing. . This is because , but is a constant. This denominator is actually known as the partition function , and that’s why its known as a “function”. However, if you want a non-normalized distribution, you can just take the product of factors.
Formalism
This is the third class of conditional models that we didn’t talk about yet. We have a set of variable and , and we define the conditional distribution as

Note how the cliques include both and now. It is possible to have cliques in this product that don’t have both. For example, in the handwriting graph, we need to connections.
We define the partition function as

This is because we observe , but we must make the distribution of legal.
Intuition
First, you can think of a CRF as a normal MRF except that we have a set of variables already observed. Therefore, you can make some conclusions about which variables are independent using the graph separation.
Second, you can think of the CRF as a joint distribution with a slightly different sum. A normal joint distribution sums to 1 across all variables. A conditional distribution also depends on all the variables, but it sums to 1 across only the variables that are not conditioned . This is why we modified the partition function.
Definition of factors
Just like in discriminative models that, we find that our factors may become intractable. For example, in the handwriting graph we need to compute , which is a map between an image and a letter. No tabular form will work! Therefore, you can use a parametric model, like a convolutional neural network to work as the factor.
And here’s something important: because we are always observing x, we don’t need to worry about modeling ! Therefore, you can use a complicated feature distribution without worrying about modeling it. But of course, it means that we don’t have the true joint distribution on hand.
This is a little tricky so think about it for a second. A conditional probability distribution is also a function across all variables, but unlike a joint distribution, these conditional distributions only are “active” on the unobserved variables.
CRF and logistic regression
Once again, we can show that logistic regression can be derived from CRF. Let’s look at this graph

If you let and , then we get

And the normalization constant is just

When you put this together, it is just the logistic regression!
CRF pros: summarized
- no dependency encoding with , which allows a large set of observed variables without worrying about their dependencies
- allows continuous variables
- incorporates domain knowledge with the graph structure