Overdetermined Linear Equations and Least squares (left inverses)
| Tags | Closed Form |
|---|
Linear equations: a deeper look
We start with . This is a linear equation, where we want to find some given .
Overdetermined linear equations
If , then there are variables and equations. If , then it’s overdetermined. Therefore, for most , there doesn’t exist an .
Geometric interpretation: We throw a lower subspace into a higher one. Therefore, we can’t possibly cover this higher space, meaning that we can’t do the reverse.
However, can we approximately solve this equation? Geometrically, it means that we find some such that is close to .
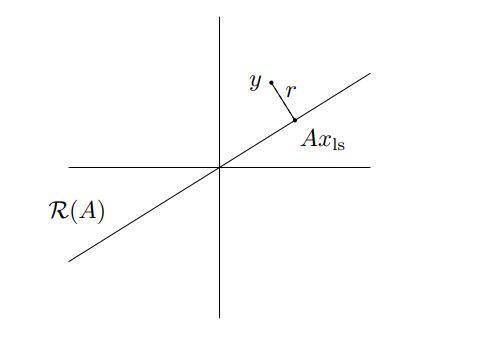
Fitting the matrix
We define the residual to be , meaning that the norm of the residual will be

This is a quadratic form, so we can take the derivative and set it to zero
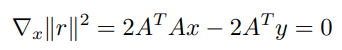
which yield the normal equations

so we get the approximate solutions as

We call

to be the pseudo-inverse of . It is also the left-inverse of .
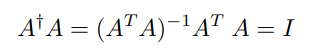
Because is a matrix that projects onto (think about it for a second…), we call the projection matrix.
Orthogonality principle & proof of optimality
Let’s calculate the residual’s inner product WRT anything in the range of
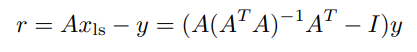
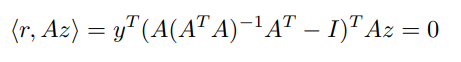
for all . Therefore, the residual is orthogonal to the range of . This makes sense graphically
We will now show that optimizes the loss (we’ve already done this through the calculus, but let’s show it again, using linear algebra). We know from our previous derivation that

Using this result, we can find another meaning for , which is the general “loss” function (this is different from , which is the least square that we derived. The pythagorean theorem and a little add-subtract trick yields

The best way to minimize this objective is to let . Neat!!
Least Squares through QR Factorization
If you can factor such that and is upper triangular, then the pseudoinverse is just
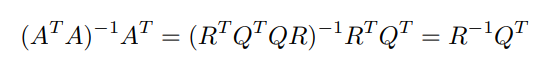
and if we project onto the range of , well that’s just

Applications
Least Squares data fitting
Suppose you had basis functions, like sine/cosine (this is a special case with fourier series), but it can be anything else too. Suppose that you had data measurements and you want to fit some linear combination of functions that matches the data as close as possible.
This now becomes a least squares problem, where you need to find weights such that

You can imagine a matrix such that . The least squares fit set is

A special case of is the Vandermonde matrix, and this becomes polynomial regression.