Optimization basics
| Tags | Basics |
|---|
Cost function
A cost function is basically how bad we're doing. We want to minimize the cost function
Likelihood
The likelihood is basically how good we are doing, in a probabilistic sense. When we maximize likelihood, it means that we are able to explain a training set phenomenon
We often do log-likelihood because a logarithm is monotonic and it decomposes products into sums
A cost function can be the negative likelihood.
Gradient descent
When we have a cost function , the gradient descent is modeled by
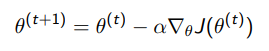
We can take the batch gradient descent over the entire dataset, or a single sample (stochastic, SGD), or a subset (minibatch)
Nuances
Batch gradient descent is guaranteed, at sufficiently small learning rates, to decrease the training loss of a convex objective every time
Minibatch and stochastic is not guaranteed to decrease the training loss due to the stochastic nature
Any optimization method will fail if the learning rate is too high
Momentum
 https://distill.pub/2017/momentum/
https://distill.pub/2017/momentum/