Matrix Calculus: fundamentals
| Tags | Backprop |
|---|
Gradient
The gradient of a function is defined as
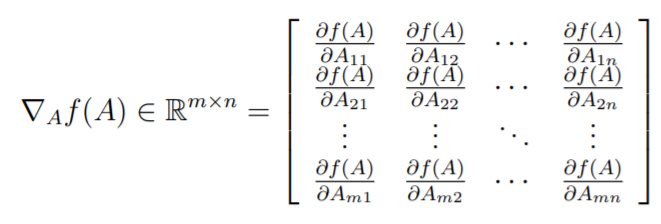
In other words
A gradient is ONLY for functions that return scalars. Gradients are technically linear transformations because these hold:
-
-
Hessian
A hessian matrix just takes in a function and returns a matrix that is symmetric, defined as
Or more graphically,
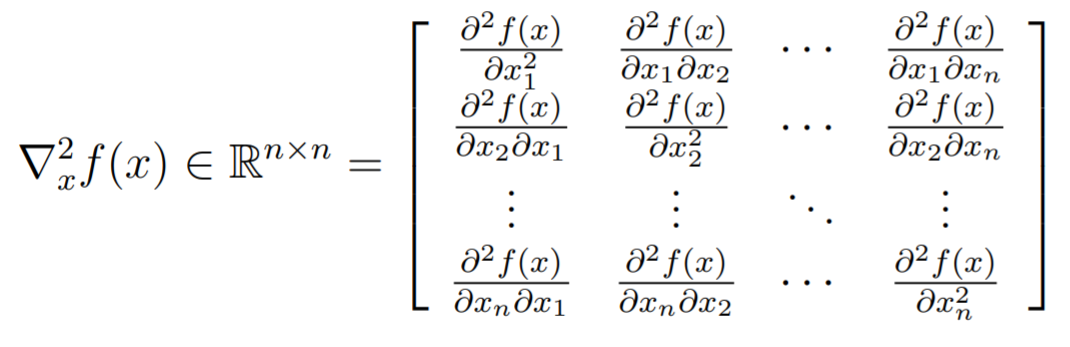
Interpretations
- the hessian is the derivative matrix (Jacobian) of the gradient
- each column is just the gradient of one component of the first derivative gradient [this is often the easiest to remember]
- The gradient is the first derivative analogue, and the hessian is the second derivative analogue
Chain rule
Chain rule is just the multiplication of Jacobians. In the case where we try to find the derivative of a matrix, just know that a matrix isn’t a 2d thing…it can be flattened. So that’s how you get out of doing things with 4d tensors. We will talk more about this in the “practicals” section, where we learn common tricks.
Micro and Macro
You will always have element analysis. But more often than not, try to use the macro properties first, as they are often more informative