Constrained Optimization: an intro
| Tags | Constrained |
|---|
The idea
What if we wanted to find the maximum or minimum of a function GIVEN that you must stay within some bounds? For example, "what is the highest point on the US interstate system?"
The intuition
Every non-extreme value must occur at least twice on a constraint surface. "what goes up must come down". However, the extreme values may occur only once! Intuitively, this means that the contour "kisses" the constraint edge without penetrating it.
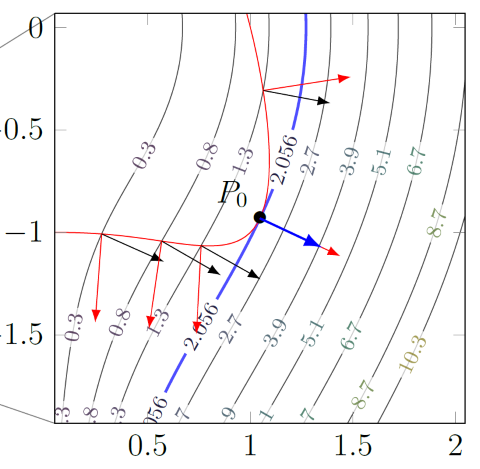
Let be the function we want to optimize, and let be the constraint. Note how is just a contour. If we took the gradient , the gradient would be orthogonal to the contour. As such, the constrained optimum can be represented by the following equation:
Intuitively, when a contour kisses , the gradients are colinear.
Solving for these points
In , the gives us equations. However, we need equations because we introduced the . This is where the comes in, with the last of the equations!
The mechanics of solving:
- solve for in as many expressions as possible, then set them equal
- if you divide by a variable, you must produce cases where that variable is zero and non-zero
- If vanishes, you must also consider that as a candidate point, as long as that is on the curve
If you're on a closed curve, then you will have two local extrema. If you are on an open curve, you can have neither.
The legrangian
The legrangian is defined as
(this can be expanded for more than two variables). The solution to the constrained optimization is when . This is not a new technique; it's just a way of packaging what we saw before into one clean equation.
Intuition of the legrangian
This really begs the question, as the legrangian seems to be able to transform constrained optimization into universal optimization. You can think of as being the function with a "penalty" component. Everywhere on the constraint, you are simply optimizing . Everywhere outside the constraint, you are either adding something or subtracting something. This "something" will prevent the legrangian from having a zero gradient, which is shown algebraically.
As an aside, you see that . Now, when we are on the constraint, . As such, we can understand to represent how the extreme values change WRT the constraint! In other words:
where is the extreme values.
Another intuition of the Legrangian
You can also think of optimizing the legrangian as doing this (or with )
If the constraint is not satisfied, then the max would cause the whole thing to go to infinity. As such, to optimize the Legrangian is to perform constrained optimization
Multiple equality constraints
If you want to optimize a function subject to two constraints, it turns out that the gradient must lie in the SPAN of the constraint contour gradients.
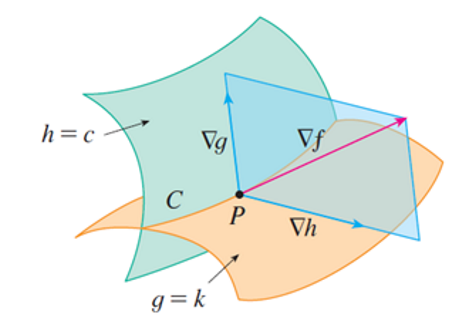
As such, . We can solve this in the exact same way as before!
Karush-Kuhn-Tucker
Here, we do something a bit harder and a bit more practical. What if we wanted to optimize a function subject to the constraints and ??
Generalized Legrangian
We create the generalized legrangian as follows:
such that .
Using the Legrangian
Now, let's attempt to find the extrema:
If , then the optimization will go to infinity. If , then the same thing will happen during optimization (currently, is negative so maximizing is constrained)