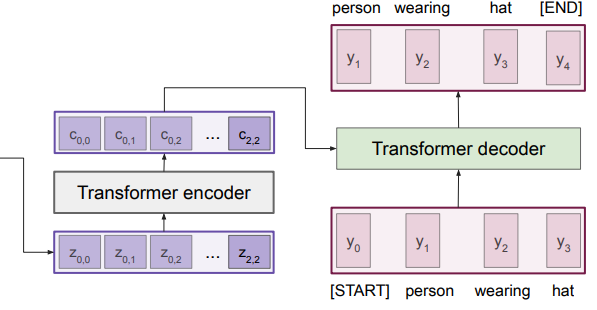
Transformers
| Tags | ArchitectureCS 224NCS 231N |
|---|
Transformer
At the heart, a transformer is a bunch of stuff around an attention layer.
A transformer takes in a set of feature vectors, encodes it, and then decodes it using attention to the encoded value. A transformer does everything separately to the set of vectors, except when attention is applied.
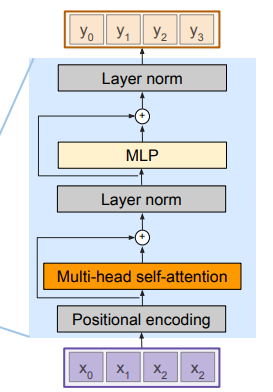
Encoder block
There are encoder blocks. In each block, we have
- positional encoding
- multi-head self-attention
- residual connection
- layernorm over each vector
- MLP over each vector
- another layer norm
The MLP is critical, because if we stack the encoders, without the MLP, attention is a linear operation and so we don’t gain much expressivity.
We add residual connections to help the gradient
Decoder block
There are decoder blocks. In each block, we have
- positional encoding
- masked multi-head self-attention (to prevent peeking!)
- layer norm
- multi-head attention (keys and values are from the encoded set of vectors, which means that the data that passes through the attention is purely from the transformer encoder (if it weren’t for the residual selection)
- layer norm
- MLP
- layernorm
- fully-connected layer
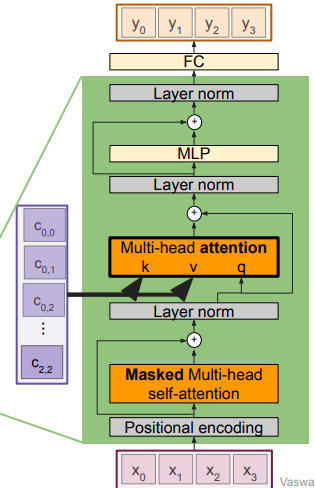
The multi-head attention allows you to mix together the encoded vector with the decoding operation.
See how there is no recurrence needed! It’s all just a big pot of things and it’s stirred slowly with the transformers.
Training a transformer
For the decoder, you can just feed in the ground truth sequence and use a masked self-attention (SUPER important) and try to match the output with the input as close as possible. Use the multi-head attention to contextualize with other information. Essentially, you feed in a squence and you expect an output of
Using a transformer
You run the decoder step by step, and you feed the outcome of the transformer back into itself (and modify if necessary). For example, in a captioning task, you would get the predicted , find the highest score, embed that, and feed it as into the input of the decoder. Keep doing this until you reach the end.