Dependency Parsing
| Tags | CS 224N |
|---|
Languages…what are they?
There are certain rules you can apply to languages, like what noun phrases, verb phrases, are, etc. And how you put them together. You can interpret this as a context free grammar.
You can also view languages as a dependency structure. Words depend on each other for meaning.
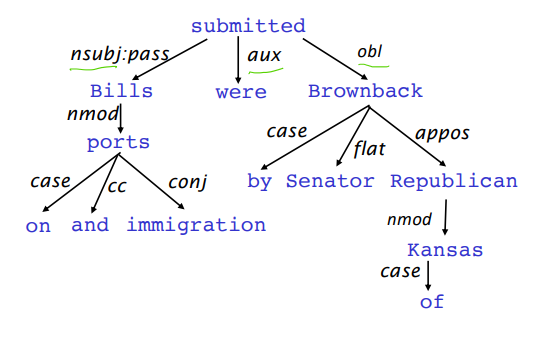
We tend to use the latter meaning of language to process it, because it helps us understand its meaning. It’s like a tree whose edges are semantically meaningful.
Why is language hard?
There is a lot of ambiguity in how languages work. Does “scientists count whales from space” mean that we are counting space whales, or are we counting whales with a satellite?
Often, modifiers are only weakly attracted to what they modify, and this can cause some problems.
Parsing
The act of parsing is creating that dependency tree.
Early attempts
If you view language as a CFG, then you can try to make a manual parsing engine. However, as we saw, language is ambiguous. So this often leaves things unsatisfactory.
Making a dataset
With the rise of machine learning, we can try doing this task with AI. We start with a dataset, which has been collected over the years
What do we need?
- Bilexical affinities (what two things are logically dependent on each other?)
- Dependency distance (how far can a dependency be?)
- Intervening material (rules about where dependencies can exist)
- Valency of heads (what is the usual number of heads, i.e. how many dependents typically latch onto a word?)
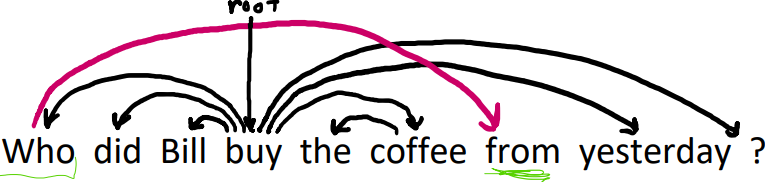
- If projections can be
projective. Aprojective parsemeans that the arcs aren’t crossing. This isn’t necessarily a good assumption, as you can get situations like this, where the purple arrow is necessary
Transition-based parsing
This is a greedy discriminative dependency parser that sort of progressively collapses text. You start with a stack which begins with the root symbol. Then, you have a buffer that starts with the input sentence. You keep track of dependency arcs.
Every move, you either shift, i.e. include another word into the stack, or you reduce within the stack by drawing a dependency arrow and collapsing
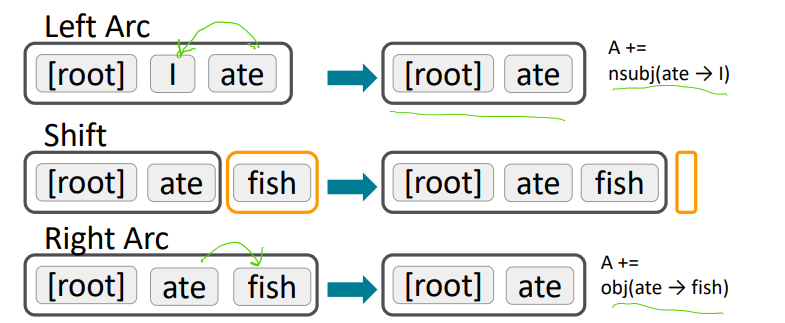
In every left or right arc, you keep the parent and collapse the child.
But how do we choose the next action? We can use machine learning. We can include some information about the sentence, and essentially create a “policy” that decides which actions to take.
Now, this algorithm only makes non-projective graphs (no arrows are crossing), which is a limitation. You can find algorithms that make it projective.
Neural Dependency Parser
Why don’t we use our handy word embeddings?
- each word represented as a dense vector
- parts of speech are also represented as a dense and meaningful vector
- extract vector set based on stack and buffer positions, and then feed this into a neural network