Attention and other Modalities
| Tags | ArchitectureCS 231N |
|---|
Integration of spatial features
This is actually really easy. You can use CNNs to reduce the image down to a set of features , and you can create an attention map using the features and a hidden representation . Then, you do the same convex combination to get your .
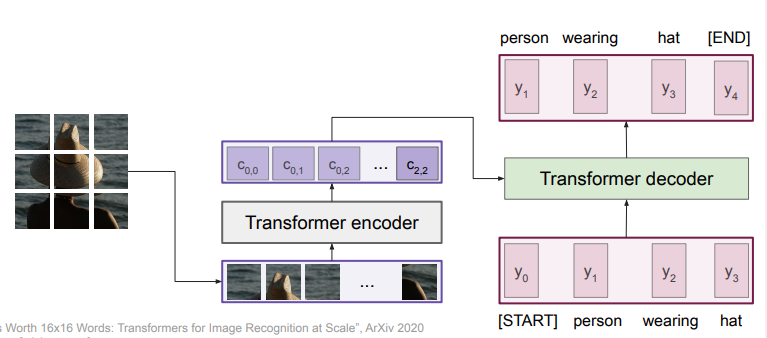
The diagram below is an image captioning engine.
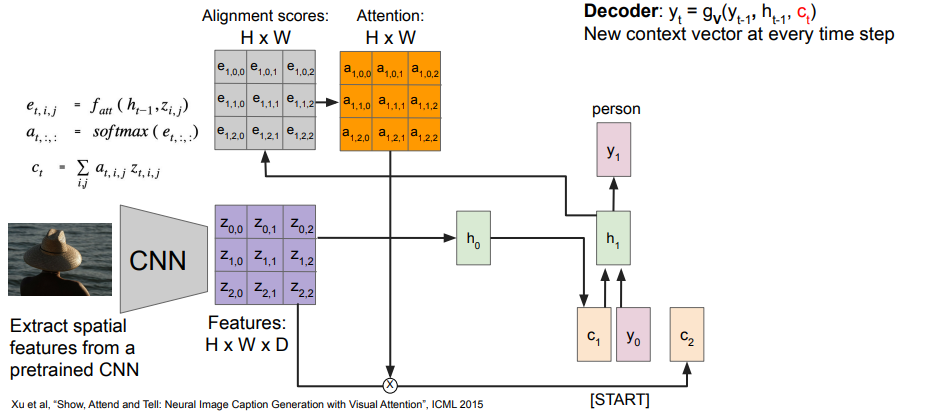
This actually gives you a really neat way of debugging your network! You can see what parts of the image are most relevant to each word generation.
Self-attention CNN
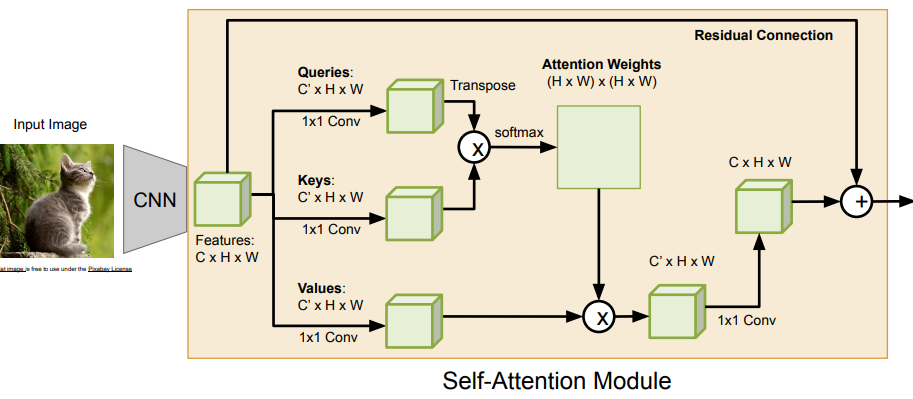
This is something that you can do on images!
Image captioning with transformers
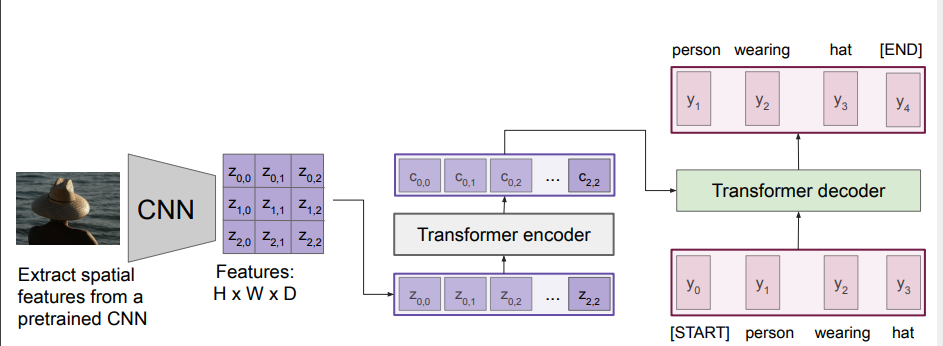
You segment the features and feed it into the encoder. Of course, this raises the question. do we even need conv nets here?
Captioning from pixels