Optimization-Based Meta-Learning
| Tags | CS 330Meta-Learning Methods |
|---|
Moving to optimization
In black-box approaches, we outputted parameters as a function of the training set . (or we did it implicitly through an RNN).
However, what we really want is some sort of “quick learning” that yields , and during learning, we use gradient descent. Can we put this inductive bias into the function ?
As it turns out, yes!
Optimization-based adaptation
We can just define
with a meta-objective being
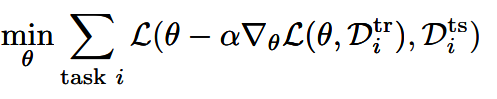
So this is essentially like fine-tuning, but we are optimizing for the ability to be fine-tuned. This is known as Model-Agnostic Meta-Learning, or MAML.
- the is typically larger than the standard learning rate, and there may be more than one gradient step. We will talk about this in a second, during the math theory part.
The algorithm

The math theory
But this raises some big questions. We are taking a gradient through an optimization procedure. Does that mean we need to take the hessian?
Actually, no! As it turns out, we can express hessian-vector products without actually computing the hessian. We will explain why we care about this in a second.
If we let , then we have the first-order taylor expansion . Now, we can express , where is a unit vector and is a scale. This means that
This means that you can solve for .
which means that you only need two points of the gradient to approximate the hessian vector.
All of this is cool, but why do we care? Well, let’s crunch the numbers and compute the gradient of the meta-objective
And of course, because relates to through the derivative, you will need the hessian.
Now, this nasty is a computable row vector that we can call . Therefore,
where is a small number.
as it turns out, Pytorch does all this heavy lifting for you, so you dont’ have to worry. But it’s always important to know where things come from.
If you take more than one gradient step, you can actually show that it doesn’t increase the order of the derivative. Intuitively, you’re applying a first derivative over and over, but you’re not differentiating with respect to it. So, while the expression becomes more complicated, the order stays at 2.
As a proof sketch, you can show it inductively. , and it yields the same form but you multiply the end by . Now, you can write and you get the same form, but you need . (note that the primes are not derivative but just updates.). You keep on going until you get to the original . So you can imagine rolling out the derivatives in reverse.
Now, due to the chain rule, all you’re doing is taking products of hessians. You are never taking a deeper gradient.
Optimization vs black-box
MAML is like black-box, but the computation graph has a gradient operator. You can also mix-and-match, where you might have a function that takes in and modifies it to form the gradient update for .
In general, because we know that optimization does something reasonable (moves us towards lower loss), it has better behavior with out of distribution or extrapolation examples. We can also show that MAML is expressive as any other network along with the power of this inductive bias of learning.
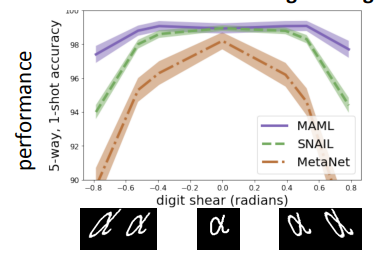
Pros and cons
One challenge is that bi-level optimization is unstable at times. Here are some solutions
- learn the along with the
- optimize only a subset of parameters
- introduce context variables
Another challenge is that the inner gradient step is heavy on memory and compute
- Crudely approximate , which actually kinda works for simpler problems, as this assumes that the optimization terrains stay roughly the same.
- Optimize only the last layer of weights (can yield convex objective)
- Derive meta-gradient using implicit function theorem (see paper Implicit MAML)
So the big takeaways is that there is a good inductive bias, better extrapolation, and model-agonistic. The cons is that it’s more memory/compute intensive and requires second-order optimization.