Multi-Task Learning
| Tags | CS 330Multi-Task |
|---|
Tasks and where to find them
Remember that a task consists of data-generating distributions and a loss function . Often, between tasks, we share certain attributes
- Multi-task classification: you usually share the same loss function
- Multi-label learning: you usually share the same generation distribution and learn different . Usually, the loss function also stays the same
- You might vary loss functions if you’re dealing with mixed data, etc
Multi-Task Models
You need to tell the model what to do, so you give it some context . This could be a one-hot vector, or it could be something more complicated. You’re essentially training .
The extreme examples
With one-hot vectors, you can essentially “gate” a neural network ensemble such that each task gets its own network. Here, there are no parameter sharing
On the other extreme, we can just inject into the activations somewhere which means that all the weights are shared
There are many ways of injection. We can concatenate with an activation or add it. These two operations are mathematically equivalent if you’re talking about linear layers, due to properties of matrix multiplication.
You can also do multiplicative conditioning, which is sort of like the “gating” thing we talked about but softer. You take the element-wise product between the task representation and an activation.
There are more complicated conditioning choices but these are the simplest.
- One notable complicated choice is to have a bunch of “experts” trained to be good at different things and then weigh the expert contribution according to relevance
Being in-between
What you can do is split parameters between shared and task-specific, with an objective of
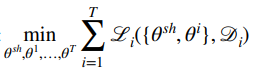
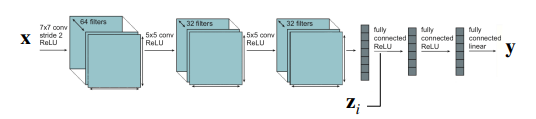
It’s difficult to choose where these parameters are though. A common way is to use a multi-head architecture, where you have a shared trunk and task-specific heads
Multi-task objectives
You can just sum up the losses
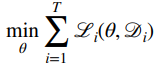
but there can be cases where you want to upweigh certain loss functions more. Perhaps one task is harder, or one task is more important. These depend a lot on heuristics
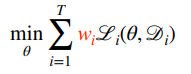
You can also use a min-max objective, which basically takes the worst task and optimizes it
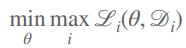
This should be used if the tasks are equally important and you to be fair
Multi-task optimization
basically sample equally from the tasks

Potential problems
Negative transfer
Sometimes, the model will perform worse with shared weights. This could be from optimization problems, or the tasks are contradictory. It may also be the case that the model is too small to represent all the tasks.
Potential solutions
- Share less parameters. You can also “softly” share parameters by adding a regularization term
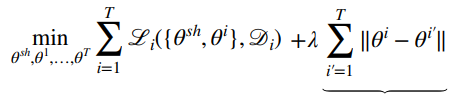
- Make your network larger
Overfitting
If your model overfits to the specific tasks, you might not be sharing enough parameters. When you share parameters, it’s like you’re regularizing the model.
What if you have a lot of tasks?
It’s hard to select the right tasks, although there are some works in the field. This is still an open problem