Meta-Learning Basics
| Tags | CS 330Meta-Learning Methods |
|---|
Why meta-learning?
Transfer learning is when you have a source task and a target task. Meta-learning looks at optimizing how well we go from source to target. In other words, given a set of training tasks, can we optimize to learn new tasks quickly?
Alternatively, we can understand meta-learning as transfer learning with many source tasks. For both transfer and meta-learning, we don’t have access to prior tasks. In all settings (multi-task, transfer, meta) we must assume shared structure.
Ways of looking at Meta-learning
Probabilistic view
We can make a PGM that looks like this
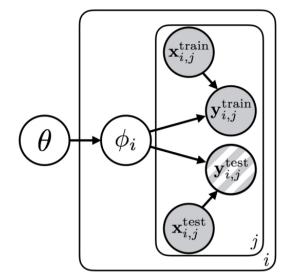
The is the parameters for each task, and the is the meta-learning information. You can interpret it as a random variable whose support is over all possible functions. if the tasks are not independent to start with, then this gives the prior to .
We can also see that
which means that if we know , we are more certain about what is.
Here are some examples; if you are fitting a family of sinusoids, the might contain the base sinusoid wave. If you are fitting a machine translation model, the might contain the family of languages. The key here is that is a narrower distribution than all possible functions, which makes it easier to learn .
Mechanistic view
This view is just focusing on what meta-learning models actually are.
In Meta-Supervised learning, your inputs are and and your output is . You have many datasets, one for each task.
Therefore, the meta-learning objective is just
where are the meta-parameters. This can be an actual model (black box models) or it can be an optimization process, or something else.
Terminology
- For the subtasks, we call the training set the
support setand the test set thequery set. This reduces confusion, as we have meta-training and meta-testing sets that are each individual tasks with a support and a query.- So, it’s actually important that we train on the sub-test set (query), which might sound wrong for a bit
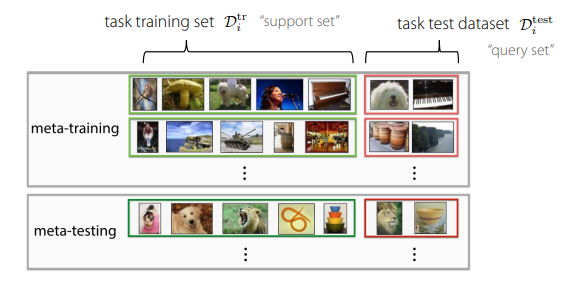
k-shotlearning means that we learn with examples per class in meta-testing. A holy grail is 1-shot learning, which means that you feed the model with one example of every desired class and it will work on other examples.
N-wayclassification means you choose between classes.
Thoughts about training and testing
Your and your doesn’t have to be sampled independently from the master dataset. You could add a lot of augmentations to the training data, like noisy labels, domain shift, etc. This can help the model generalize to the test set, just like non-meta augmentations can help a model generalize.