Frontiers and Open Problems
| Tags | AdvancedCS 330 |
|---|
Meta-Learning and Distribution Shift
A problem that we’ve talked about is distribution shift. We have some approaches in domain adaptation, etc.
Distribution shift is very important, because as society evolves, certain things change. Machine learning models need to keep up with the change.
The first idea that comes to mind is fine-tuning. While it is reliable, it also requires labeled data and is computationally expensive. It is quite a blunt tool. Can we do better?
Dealing with Domain Shift
Domain shift is when we have some domain variable underlying the distribution of .
Adversarial Domain Training
You can try to find the worst possible domain to train on. This is known as Group DRO, and often it leads to robust solutions. However, it typically sacrifices group performance.
However, the overarching problem is that we are doing a ton of preparing beforehand, and then just hoping for the best during test-time. Can we adapt to things as they come?
Adapting to a Domain
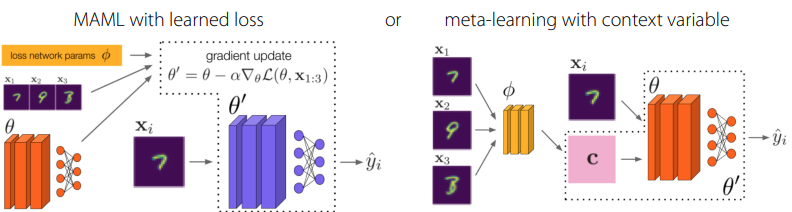
Indeed, we can try to adapt to the test set domain using meta-learning! In this particular setting, you have unlabeled test set data. We want to use this data to adapt the model and then use this adapted model to assign labels. This is known as Adaptive Risk Minimization.
You can run MAML but with a learned inner loss (remember: there are no labels!). You can also use black-box learning with a context variable derived from the whole set.
Dealing with Concept Shift
In domain shift, typically you have as saying the same while you change . However, there can be situations where this indeed changes and you have to deal with it. This is especially relevant for large language models, where the answer to a question might change as society changes.
Editing these large language models are hassle, as they require a lot of computational resources, and they might suffer from overfitting. Furthermore, one correction point should impact a broad range of questions that are conceptually related.
We can frame model-editing as meta-learning. We create an “edit dataset” that contains an edit descriptor, a locality enforcer, and a generalization enforcer. Here’s an example.

You can try to learn a neural gradient filter, which takes in the gradients yielded by a fine-tuning gradient step and modifies it through a neural network. Technically speaking, this model only takes in a rank-one update, which allows it to be more computationally efficient. More information in the paper, Fast Model Editing at Scale.
You can also try to store all the corrections and reference them when needed.
Meta-Learning across General Task Distributions
Learning a Generic Optimizer
A recent paper, VeLO, showed that you can train an optimizer that works better than Adam on a large spread of models. Essentially, you keep a small MLP for each parameter (yes, this is quite expensive) that outputs the parameter update.
You use an LSTM across a weight tensor to generate weight matrices for each of the small MLPs. The LSTM also outputs a global context vector that is shared for all weight tensors.
This is incredibly computationally expensive, but it yields pretty good results.
Learning Architecture Similarities
Sometimes we use specific architectures because we know that the data has a certain property, like convolutions. But can we learn it?
We can split the weights into an equivariant structure and its corresponding parameters. We can do this because we can always represent a structure through a matrix multiplication, even if it’s a little weird. Here’s an example with 1d convs.
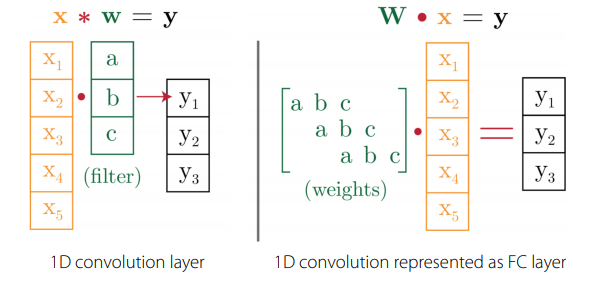
So we can use a matrix that captures the parameter sharing and compose it with the underlying filter parameters. In the inner loop, you only optimize the filter parameters. In the outer loop, you optimize the parameter sharing matrix.
Open Challenges
Long tailed distributions: how can we deal with rare data?
Multi-modal inference: can we use things like text to help reason over images, etc?
Good benchmarks that mimics real-world problems
Improving core algorithms. Can we reduce computational complexity?
So far, machines are specialists, but humans are generalists. Can we make machines generalist?