Domain Generalization
| Tags | AdvancedCS 330 |
|---|
What is domain generalization?
Domain generalization is using the same setup as domain adaptation, but this time, you are not allowed access to the target data. Moreover, you don’t necessarily have access to the source data once exposed to the target. As a good example, imagine making a self-driving car algorithm that works on a set of roads. You would like it to work on a new road without doing any training
You can think of domain generalization as zero-shot success to something new, where the truths are the same but the underlying is different.
As a more formal way of seeing it, domain adaptation is transductive , meaning that we propagate knowledge from what we are given, to the target task. Semi-supervised learning is an example of this. Domain generalization is inductive, meaning that we will make general rules about the task that carry over to new domains.
- another difference is that there are multiple source sets in domain generalization
What can go wrong?
Well, it can be that between domains, you can have a spurious correlation. You might have a water domain where you se a lot of dogs, and a grass domain where you see a lot of cats. In this case, the model will probably learn to use the background of the image. Instead, what we really want is a model that predicts dogs and cats pretty well, regardless of the domain.

Explicit Regularizers
Adversarial paradigms
We can train representations that are explicitly domain invariant. This can be done similarly to domain adaptation, where you maximize confusion on a domain prediction model. Simultaneously, you maximize the downstream task performance
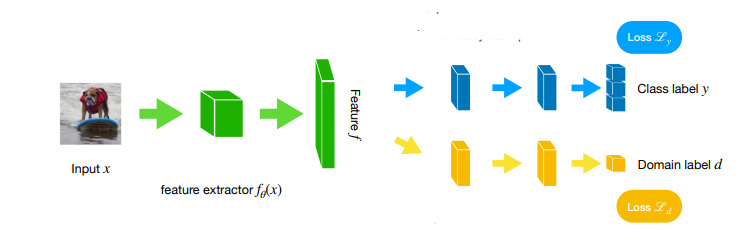
you train on all source domains.
Representation alignment
instead of using an adversarial paradigm, you could try to tie cross-domain embeddings somehow. To do this, you might try to have the embeddings have similar covariance matrices. Intuitively, when you’re doing classification loss, you’re only really doing first-order fitting. The variances between domains might show up in the “shape” of the distribution, which we remove by pushing the covariances close together, which is a measure of “shape.”
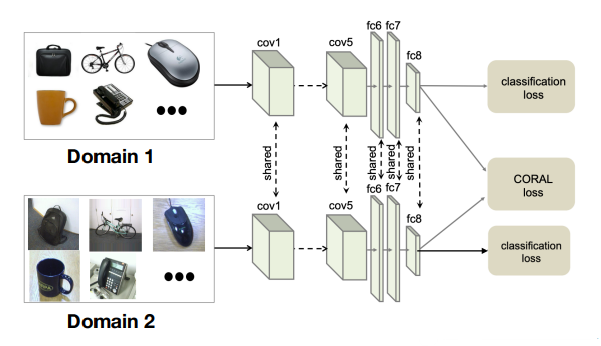
Data Augmentation
If we could collect more data, we often break the spurious correlation. While this is ideal, it may not be possible to collect more data. But…it’s possible to generate more data through augmentations.
Mixup augmentation
You can essentially mix together a collection of data and try to fit the model to output the right mixture of labels.
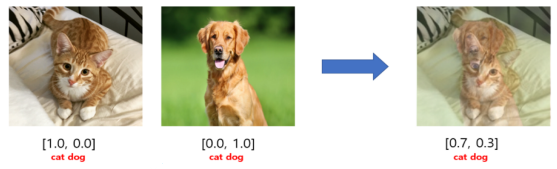
While this allows you to get a ton more data, it doesn’t really solve the spurious correlation problem.
Improving Mixup
Mixup out of the box doesn’t help, but we can modify it to help.
We can try intra-label Mixup, which takes the same label from all domains that mixes them together. In our dog and cat example, you would take dogs from all locations and mix them together. You would still fit them to the same label. This essentially helps with background augmentation.
The problem is that if there is still a water majority for the dogs and a grass majority for the cats, you might still encounter some fixation on the background. You can solve this by sampling equally from each domain, or you can use intra-domain mixup.
In this case, you apply the standard mixup algorithm to within one domain. This signals to the model that the spurious domain features do not affect the label change. For example, we might have a mixture of grass cat and grass dog, and if the model is fixated on associating the grass with cat, the model will not do well when shown shown this mixture.
So… which one do we use?
- Intra-label allows you to create essentially an infinite number of domains. IF the spurious correlations between domains isn’t that strong, then this could be the way to go
- If the spurious correlations between domains is quite strong, intra-domain mixup provides a stronger signal against the correlation
But at the end of the day, just remember that both approaches disrupt one part of the correlation, so they both have some effect. In reality, we actually randomly sample the augmentation technique per batch
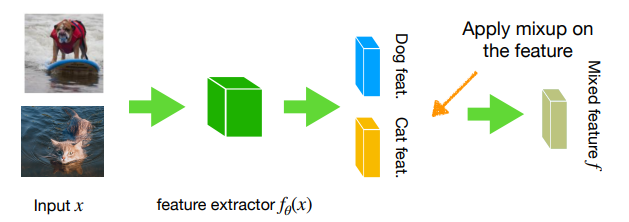
Manifold mixup
sometimes, it doesn’t make much sense to mix high-dimensional features. Overlaying a cat on top of a dog may not be as meaningful as overlaying the features of a cat on top of a dog later in the processing stream. As such, we can do manifold mixup, where do exactly this: mix the features!
Pros and cons
Regularizers:
- Regularizers are often data and model agnostic
- you are given some guarantees theoretically
- however, the regularizer can be too harsh. What if we want the shapes to be different? Etc.
Augmentations:
- easy to implement and understand
- however, it is largely limited to classification