Advanced Metalearning
| Tags | CS 330Meta-Learning Methods |
|---|
Memorization problem
When can a metalearner memorize the tasks? Well, consider the case that you also add a task identifier
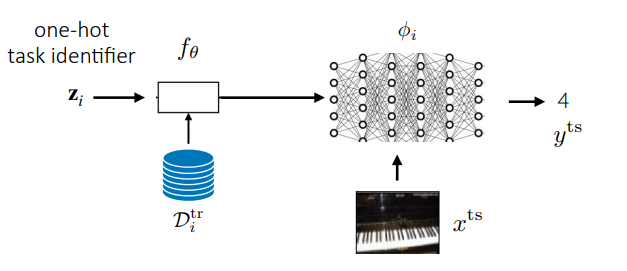
This task identifier is essentially redundant to the support set, and it’s much easier to use the task identifier to modify the network behavior. So, you might get good fitting but at test time, nothing works.
Now, this might seem like an obvious problem, but a similar thing happens in other domains too. If you have a consistent label assignment (i.e. images of one class always get mapped to one label), the network can essentially learn a massive classification model (that maps multiple types of images to each label class) and ignore the support set.
Task inference
But for images, this is a trivial problem to solve. Just randomize the labels! The problem comes when task inference is inherent to the setup. For example, if you have this

you might end up making a model that is conditioned on the initial frame. it just knows all these tasks and decides what to execute based on what it sees first. This is a problem when you give it a test task.
Similarly (and more trickily) you can have a model memorize the canonical orientations of every training object and use that to predict the orientation without even using the support set. But this gets it in trouble when it sees a new image.
Preventing memorization
If tasks are mutually exclusive (i.e. a single function physically can’t solve all tasks), then metalearning will be successful. But more often than not, there are two solutions to the meta-learning problem.
- Memorize certain information about tasks in and care less about the support set
- acquire all data from the support set.
The latter is what we want, but often the former is easier to do. Ultimately, it boils down to how much influences the output, and how much influences the output. To push ourselves to the former objective, we want to maximize the mutual information bewteen and . But this mutual information objective is hard!
Instead, we can use an information bottleneck. We first define a gaussian with means centered at the current values of , but during adaptation, we sample from the gaussian. We also try to keep this close to a prior , which essentially keeps the parameter set simple.
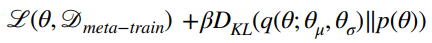
this is essentially like regularization, and we call it MR-MAML (meta-regularized MAML)
We can actually provably show an upper bound on generalization error.
Self-supervised task generation
Where do tasks come from? For certain things, it’s easy. Just make a subset of classes to form your task. But what if you have a bunch of unlabeled data?
Well, we can propose tasks! These tasks should be diverse but also structured (you can’t just group a bunch of random pictures together under each label and expect things to work)
Unsupervised Metalearning
The idea is acdtually pretty straightforward
- Generate embeddings of the image using existing embedders
- Create clusters in the embedding space (like K-means)
- Propose cluster discrimination tasks
You’re essentially making your own labels!
Using domain knowledge
You can make your own tasks from each image
- select images, and assign them to a separate class
- Augment them using domain knowledge for the support set
This actually works quite well on Omniglot, and even on imagenet.
What about unlabeled text?
We can construct tasks by masking out a set of words and then asking the model to give the word that is masked out.
