Advanced In-Context Learning
| Tags | AdvancedCS 330 |
|---|
GUEST LECTURE PERCY LIANG
Why is in-context learning cool?
This is an emergent behavior in large language models like GPT-3, and it is the ability for the model to yield meaningful few-shot responses without any fine-tuning. Essentially, in-context learning is a black-box method that calculates the posterior after conditioning on all the inputs:
Transformers are not just memorizing and copying some content it saw from the internet; you can devise tests that show that it can bind associations very quickly.
What can Transformers Learn?
We can understand in-context learning as inferring a function class. You select a function, sample from this function, and they query the model at an unknown point.
For these experiments, the authors looked at simple linear functions first. We train the transformer to do few-shot regression.
They showed that
- Transformers learn a least-squares-like algorithm when faced with this linear regression problem
- Transformers extrapolate well to different distributions, and it even exhibits double-descent when given a noisy data to overfit to
Then, they tried more complicated functions.
- Transformer matches lasso functions when dealing with sparse linear functions
- When dealing with decision trees, it even outperforms XGBoost algorithm
- the larger the model size, the better it is as extrapolating
In-context learning as bayesian inference
You can model the data as a graphical model with an unobserved central generating parameter
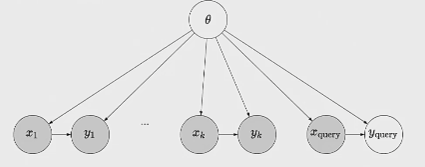
and you want to run inference on . To do this, you need to marginalize out the , and so you can think about the transformer as doing this part of inference. Or, you can think about the transformer as inferring the latent concept .
Challenging the learner
You can try essentially switching the partially through the prompt. For example, your prompt sentences might share some general idea, but the subject matter might be very different. You want the model to infer this general idea, and not just the subjet matter. Here’s an example of such a prompt:
Albert Einstein was German. Mahatma Gandhi was Indian. Marine Curie was...
This is in contrast to something like just a paragraph summary about Albert Einstein
You can also prompt using random labels, and it still seems like the transformer gets something out of the context. This is in contrast to supervised learning settings, which would tank if you randomized the labels. Why are the transformers so robust? We can use a bayesian explanation again! Because there is implicit inference going on, there is a denoising process.
Similarly, we can switch the labels consistently, and the transformer seems to do quite well.