Eigenvalues and Eigenvectors
| Tags |
|---|
Eigendecomposition
Properties of Eigenvalues
- Always, if there is an eigenbasis, then the eigenvalues of is just . Proof: use diagonalization
- invariant to a rigid transformation (duh)
- Adding to a matrix will add to all its eigenvalues
- If an eigenbasis exists for , then for obvious reasons. But this is a nice property to know.
Gradient of eigenvalues
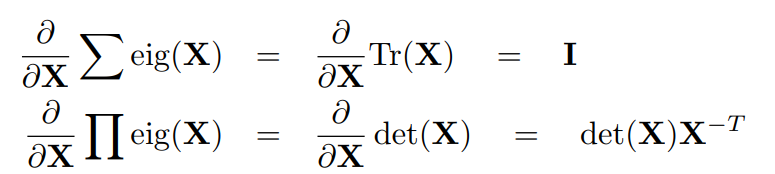
Sum and product of eigenvectors
The trace of a matrix is the sum of eigenvectors!
The determinant of a matrix is the product of eigenvectors!
Other Properties (cheat sheet)
- The determinant of is the product of its eigenvalues
- An eigenvector is defined as , which means that . We can use this to create a polynomial in whose roots are the eigenvalues.
- The trace of is the sum of its eigenvalues
- The rank of is equal to the number of non-zero eigenvalues of
- Inverse matrices have the same eigenvectors as the original matrix but with eigenvalues as multiplicative inverses of each other.
- have the same eigenvalues. This goes back to
- similar matrices have the same eigenvalues but not necessairly the same eigenspaces
- Proof: . This means that . Therefore, the characteristic polynomials are the same, and therefore the eigenvalue are the same
- Cayley-Hamilton Theorem: , for a diagonaliable matrix (i.e. when you plug the matrix into its characteristic polynomial it always yields a matrix of zeros. Interesting!
- proof: . Therefore . Now, because each element of is a root of the characterstic polynomial . Neat!!
- for a square matrix, eigenvectors that correspond to distinct eigenvalues are orthogonal (spectral theorem, more on this later)
- right and left eigenvectors are linearly independent sets
- eigenvectors corresponding to distinct eigenvalues are linearly independent
Creating eigenvalues
Invariant subspaces
An invariant subspace in is defined as the following: for all , we have that . Some examples of invariant spaces include the null space and the range of , but also some other special vector spaces known as eigenvectors
Eigenvalues are defined under the following four equivalent conditions
- is not injective
- is not surjective
- is not invertible
-
It is this last point that we arrive upon the definition of the characteristic polynomial
Characteristic polynomial
is the `characteristic polynomial of . The roots of the polynomial are the eignvalues.
- you can plug in matrices into polynomials if you want!
The eigenspace is just , and it corresponds to all the vectors with eigenvalue
Multiplicity
The algebraic multiplicity of an eigenvalue is defined to be the dimension of the corresponding generalized eigenspace . The geometric mulitiplicity is worried only with .
- the algebraic multiplicity of an eigenvalue is just , because we have shown that the generalized eigenspace is equivalen the null space of
The sum of multiplicities is equal to
Mathematically, if , then has algebraic multiplicity
It is possible for geometric multiplicity to be strictly less then algebraic multiplicity, This is called being defective. In other words, there are some vectors that don't become eigenvectors until the is raised to a higher power. A defective matrix is not diagonalizable, while a non-defective matrix is diagonalizable, meaning that it has an eigenbasis
- in this case where is your eigenbasis and is your diagonal.
Eigenspace
An eigenspace is just the span of all eigenvectors with eigenvalue . Alternatively,
The sum of eigenspaces is a direct sum, because different eigenvectors with different eigenvalues are linearly independent
Basis of eigenvectors
Sometimes you can have a basis of eigenvectors, which means that you have such that . The matrix of WRT this basis is just a diagonal, whose entries are just the eigenvalues
If such a basis exists, then you can find a mapping to this basis and represent the map as or , depending on how you prefer to write it.
We will see some results involving this idea below
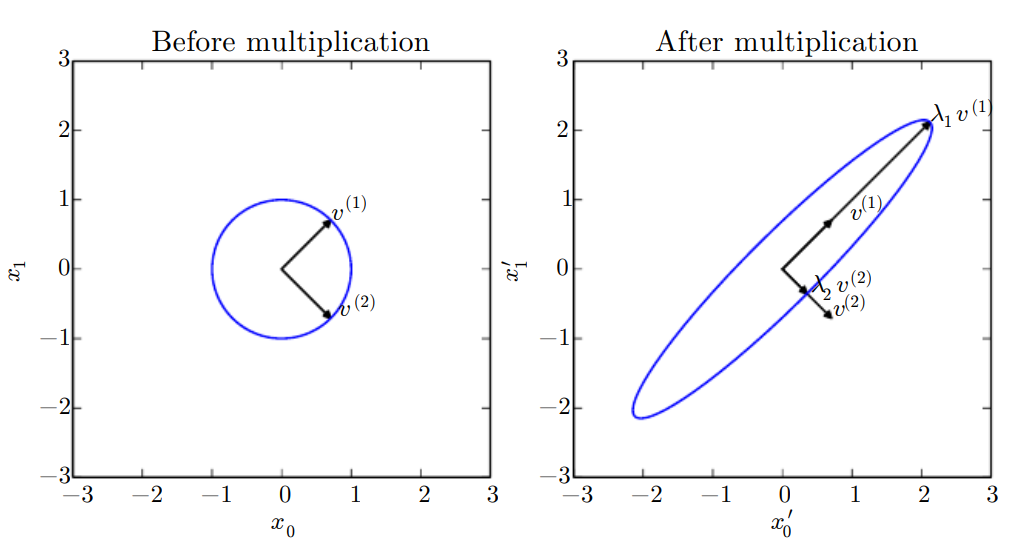
Another way of thinking about this
A square matrix has an eigenbasis if you can do (or the other way around). As such, you can think of an eigenbasis as being able to stretch and shrink space in desired directions
Diagonalization
We will build up the intuition why . First, let's consider , where is a column matrix made up of the orthonormal eigenbasis . This is as follows: (note that they use a slightly different symbol for the diagonal)
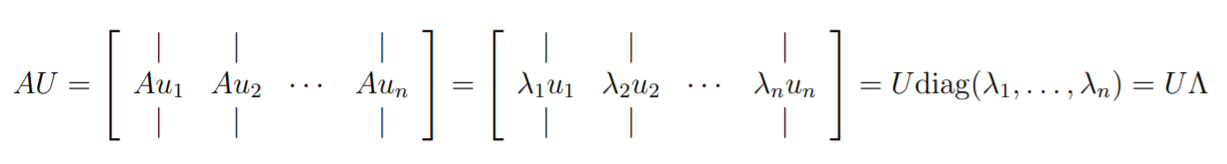
Now, note that , so we get the following:
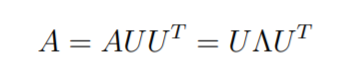
The importance of diagonalization
You can think of as a map that takes in vectors in an eigenbasis and pushes it over to the canonical basis. As such, takes the canonical and moves it to the eigenbasis. This is why it's and not the other way around.
Matrix-vector multiplication and matrix exponentials become very easy when dealing with an eigenbasis representation
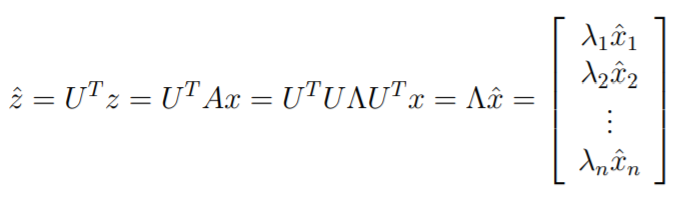
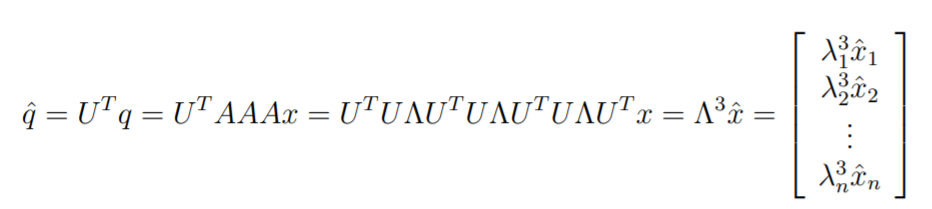
Other Formalities
Right and left eigenvector
A right eigenvector is such that
A left eigenvector is such that .
We will care more about right eigenvectors mostly.
Duality
The tranpose of a right eigenvector is a left eigenvector of , and the tranpose of a right eigenvector of is a left eigenvector of . You can prove this by tranposing the equation
- you can also use this trick to find left eighvectors for easily using the characterstic polynomial of
Properties
Quadratic form decomposition
If you have , you can split it up into
Why? Well, the is the projection operation, which is equivlaent to inner product for unitary vector. Sigma scales, and associative property means that we can do .
Davis Kahan Theorem
If are symmetric matrices and , then
where represents an eigenvalue of , and represents an eigenvector of .