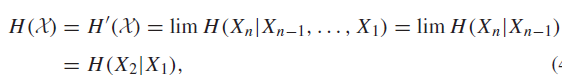Stochastic Processes
| Tags | BasicsEE 276 |
|---|
Stochastic processes
A stochastic process is just a sequence of random variables with a joint probability mass function.
We call a stochastic process stationary if the joint mass function doesn’t depend on shifts in the time index. Intuitively, it means that there’s some sort of pattern in the distribution. Automatically, IID stochastic processes are stationary.
Entropy Rate
So previously, we had a nice notion of entropy because we had IID variables and we could just take . Now that we have a stochastic process with potentially evolving variables, how do we give a measure of entropy?
Here, we look at a measure called the entropy rate.
The definition 🐧
We define the entropy rate of a stochastic process as
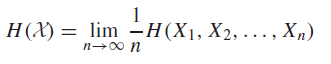
Now this can be interesting. Consider a few examples and types of behavior
- IID: , so . So it doesn’t contradict an existing definition.
- independent but not identically distributed: limit may not exist, as the average may oscillate
We can also define an alternative entropy rate measurement
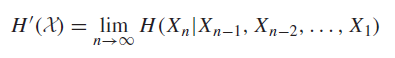
They measure slightly different things, but we will relate them in the next section
Stationary Stochastic Processes equates 🚀
Theorem: if a stochastic process is stationary, then
Proof
To start, we need to show that exists. From conditioning properties and stationary properties, we have
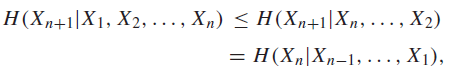
Therefore, we have shown that the is monotonic and bounded (entropy non-negative), it does converge, so exists.
To continue, we use a simple analysis result (Cesaro mean): if and , then . This is a simple epsilon proof
proof
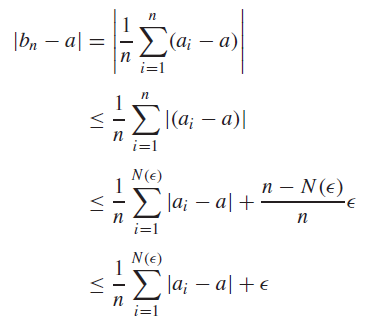
Now, from the chain rule, we know that
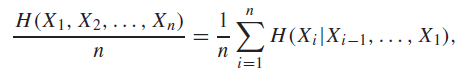
let LHS be . We know that , so by the Cesaro mean theorem, we have
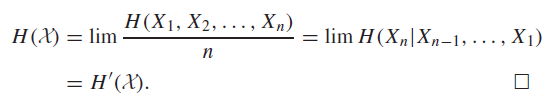
as desired.
Markov Chains
In the AEP section, we talked about IID variables, which is a good start, but we seldom deal with IID characters in real life. Here, we move to another level of complexity, where we have random variables that satisfy the Markov property.
The best way of thinking of a Markov Chain is as as journey of samples, in accordance to the Markov probabilities. You record this sample down as the stochastic process. You look at general behavior: what do a distribution of such samples look like? At the end of the day, it’s just a joint distribution with special properties.
PGM view
Markov chains are just PGMs such that every pair in the PGM has only one active path.
The key idea
If you took a random slice of a markov chain, you get some random variable . This can be distributed like anything. If it’s in the stationary distribution, then any slice shares the same distribution statistics. Now, even though every slice shares the same statistics doesn’t mean that it’s IID! There is a dependence, which is captured by the .
Therefore, you might have two that are all identically distributed, but they have a dependence.
Markov Properties 🐧
Remember that the markov property means that you can factor the joint distribution as so:
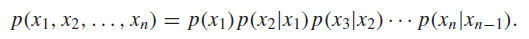
which means that you can express the following relationships between samples:
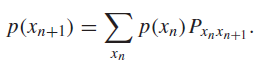
Intuitively, we’re just making a joint distribution and marginalizing. This is also equivalent to , where is a vector of probabilities that represents .
Markov chains are time invariant if is agnostic to . This is different from being stationary (more on this in a second). We can express the a time invariant Markov chain through a matrix where . All columns of the matrix sum to 1. Matrix multiplication is just a weighted sums of the columns, which is guarenteed to be a distribution.
The Matrix
The matrix is quite special.
- If the markov chain has a stationary distribution, then it has an eigenvector with value .
- Repeated powers of converge to the stationary distribution, where every column represents the stationary distribution. Why? Remember that matrix multiplication is also seen as taking the weighted combination of columns. This means that for any , where is the stationary distribution
- You can easily calculate . This can be proven by doing the standard marginalization. The marginalization is exactly the same as matrix multiplication in this case.
Special Properties 🐧
- If we can get to any arbitrary state from any arbitrary state (i.e. there’s no “death” state in between), the Markov Chain is
irreducible.
- If you can group the states non-trivially such that all transitions flow from one group to another, then the Markov Chain is
periodic. As a concrete example, If you had and then , then it is periodic with . In contrast, if you had , , and had no connection back to , it isaperiodic. More formally, if the largest common factor of the lengths of paths from states to themselves is , then it isaperiodic.
- If (note their relationship from previous section), then the distribution at time is
stationary(drawn directly from the definition of a stationary distribution)
If Markov chain is irreducible and aperiodic, then the stationary distribution is unique and a convergence point.
You can solve for convergence points by using the vector definition: . Usually, this gets you an equation that can’t be solved directly (it’s underdetermined) but you can use the final constraint that . When you solved for all , you have a stationary distribution!
Entropy of Markov Chain
In general, you can find the conditional entropy by using the vector definition.
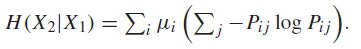
and this is taken directly from the definition of conditional entropy and the meaning of and .
Entropy Rates
As long as the distribution is stationary, then
So the limit is just , where we draw from the stationary distribution. We can calculate this value by using the stationary distribution and then the of the Markov matrix.
Alternative derivation