RV Convergence
| Tags | BasicsEE 276 |
|---|
Convergence of Random Variables
What is a sequence of random variables? Well, maybe think about dice that come out from a dice factory. Each dice is an RV, and there may be a pattern in how the dice behave.
There are different notions of convergence.
in distributionmeans that we converge to the same sufficient statistics
in probabilitymeans that for every , we have . Intuitively, the probability of an “unusual” outcome becomes more rare as sequence progresses. Close to the idea of a hoeffding’s inequality, useful for the law of large numbers, etc.- with this inequaltiy, you can say that we asymptotically bound this property within an epsilon ball
- Formally: for every , there exists some such that for all , we have . Note how this depends on both the delta and the epsilon.
in mean squareif as .
with probability 1(almost surely) if .- this is different from 2) because we take the limit inside the probability.
Notation-wise, we use for distribution, for probability, etc.
Understanding what convergence means
Distributional convergence makes sense. But how can the other types of convergence happen if these are random variables? Well, there are two common cases:
- The DIRECTLY, and as . In other words, there’s some sort of coupling between the RV’s.
- The is a constant. Here, we get some standard things like the central limit theorem, where (overload of notation), and is the mean of the current samples.
Markov’s Inequality
We can show that for any non-negative random variable and , we have
Intuitively, as we get further away from the expected value, the likelihood decreases. This is mathematically super helpful as it relates probabilities to expectations, and we will use it to build up law of large numbers.
Proof (integral definition of probability and expectation)

Chebyshev’s inequality
We can show very easily that
where is the variance and mean of , respectively. This brings us closer to the idea of hoeffding’s inequaltiy and the law of large numbers.
Proof (Markov’s inequality)
Let
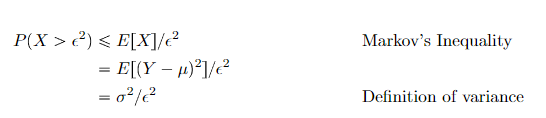
Upshot: to show the law of large numbers for any stochastic process, it is sufficient to show that the variance of the sample goes to zero.
Law of Large Numbers
Lemma: Sample variances
The variance of is
Proof (from definitions)

The actual Law ⭐
Both the weak and strong forms of the law of large numbers state that the average of samples (denoted by ) converges to .
The weak form states that the convergence happens in probability. Formally, this means that
Proof (Markov’s inequality and sample variances)
Let
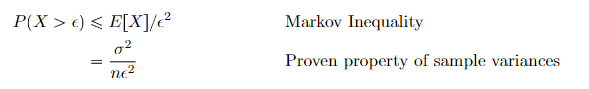
which gets us
and as we can see, the limit of the RHS pinches to 0, and that is what we wanted to show.
The strong form states that it happens almost surely. Proof is omitted for now.