Noisy Channels
| Tags | EE 276Noise |
|---|
Proof tips
- Expand as we know .
- If confused, try adding a weird state directly into the entropy and removing it through chain rule.
- is a convex function of for any given . Convexity in this case means treating the distribution like vectors.
- If it doesn’t work on first expansion, try a different expansion
- for matrices, make sure to watch out: if the rows sum to 1, you can’t do matrix-vector multiplication
Moving to Noisy Channels
Now, we are graduating onto channels that have noise, i.e. you send in some and you get . What does that look like? Well, previously we had info → encoder → decoder → info. Now, we need info → encoder → channel encoder → NOISE → channel decoder → decoder → approximate info
The Assumptions
Our job is to make this meaningful channel encoder and decoder.
IID Uniform inputs: Fortunately, we can actually make a key assumption about the data going into this set of encoders. Because we assume that we have a good data encoder algorithm, we can assume that the input is binary RV’s that are IID. Why IID? Well, if the variable had any sort of correlation, we can further compress until they are maximally orthogonal, in terms of probability.
By assuming that the input and output are just binary streams, we can actually start thinking about them as numbers that these binary things represent. Our goal is to send one number and reconstruct it as accurate as possible.
Discrete and Memoryless Channel (DMC): we can assume that the noise is memoryless, i.e. . This is very similar to an IID assumption.
The channel goes . We can’t assume any IID of the X or Y.
Nomenclature
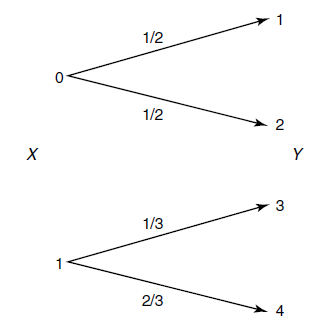
We use an arrow diagram to denote the distributions over outcomes, which can be helpful to visualize thing
Performance Metrics
There are two things we care about
- Reliability: Can we have ? (where is the whole message)
- Rate. Can we maximize the number of information bits per channel symbol?
Intuitively, these two metrics are battling. You can easily get a very reliable code if you have a really redundant signal, but this tanks your rate. Vice versa. In a later section, we will look at how these things aren’t necessarily competing if we do things correctly.
Channel Capacity
Why we can’t just take the percentage of mistakes
So the big question is: how do we quantify how good a signal is? We can’t just subtract the average number of mistakes, because you can have a channel that is maximally uncorrelated with the input, and still not make a mistake 50% of the time (just by pure chance, if you guess a binary digit, it matches the source 50% of the time). Furthermore, sometimes you lose more than the average number of mistakes, as you don’t know where the mistakes are.
Moving to capacity
Instead, it helps to think about the correlation, or mutual information between the source and the output.
There’s something interesting about this setup. Mutual information depends on , which is factored into . Now, is a property of the transmission system. It’s that you can modify.
Therefore, we define capacity as
As we will see, there’s a strategy in how we design . We want to have each to map to as far separated as possible, such that the inverted is as noiseless as possible. This is actually a concave function because Is concave in .
Meaning of capacity
Interestingly, this has a key meaning: below the rate of , you can send information with as high of a precision as possible!
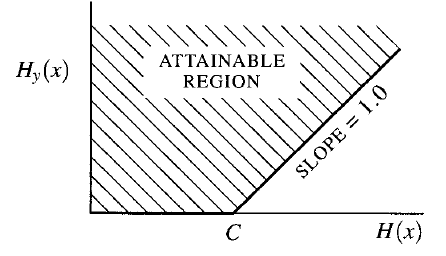
We will prove this fact in the next page of notes.
Properties 🚀
- non-negative (due to mutual information)
- because and vice versa
- continuous
- concave (but no closed form solution, typically. We use other strategies to get it solved)
How to optimize 🔨
So this objective is not very easy to optimize directly. You can use a few tricks
- . This is helpful because is maximized through a uniform distribution, and is often easy to derive.
- Now, the tricky part is to figure out (often) how to create a maximum entropy using . You might benefit from , which gives you a more direct formulation. The only problem is that the is now convoluted.
- You can also brute-force. Start with a representation of . If you have a conditional probability matrix, , then . Using , you wil also be able to derive . Usually, this sort of brute-force optimization is messy and requires some sort of crucial insight. But it can be helpful to set it up this way.
What is rate? Capacity?
Rate is the number of message bits per channel bit. Capacity is also measured in the same units, and can never exceed for binary channels. This is mathematically true because the Bernoulli RV .
Rate is determined in the encoder, i.e. the transfer from . The capacity is determined by the channel. The theory we develop will relate the rate to the capacity.
Example of Noisy Channels
Noiseless binary
Here, we consider a degenerate case where we have no noise at all. In this case, , which is maximized with a uniform .
Non-overlapping outputs
Consider the following distribution (repeated from nomenclature diagram):
This looks noisy, but actually, is noiseless. So the channel is also maximized with a uniform . This is a good example of how the expansion is critical.
Binary Symmetric ⭐
Here, the inputs are complemented with probability . So everything that we receive is unreliable, but that doesn’t mean that we can’t send anything. We’ll see an algorithm later.
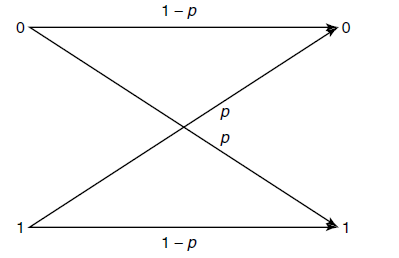
We can show that binary symmetric mutual information is bounded by : . If , it is impossible to carry any information.
Proof
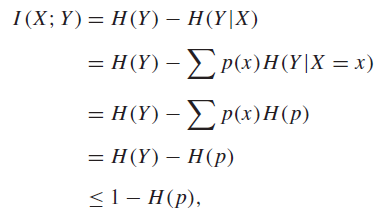
Two tricks: 1) we discovered that the second term doesn’t depend on , so we are off the hook. 2) we assert that it is possible to achieve by feeding in a uniform input, by symmetry. These are two tricks that are specific to this problem.
Now, this has some interesting implications. At any given , there are bits of information left uncorrupted. However, if you plot the line vs , you will find that the curve of goes below the . This is intuitive; it means that by randomly flipping some bits, you lose more than just the proportion of bits you flipped, because you don’t know where they got flipped.
Properties of (can be important)
The input is Bernoulli, the bit-flip is Bernoulli, so the output is also Bernoulli. If input is and flip is , then the distribution is , or .
The conditional entropy is the same as , because the entropy of does not depend on (hence the symmetry). Therefore, . Nice! This makes a lot of sense.
Binary Erasure ⭐
Here, instead of corrupting bits, we just lose some bits with probability
We can actually derive exactly what is: . This is intuitive, because if we lose proportion of bits, we can only recover bits.
Derivation
So this structure yields something hairy, because there’s this death state, essentially. We can start with this original expansion
But how does depend on ? And is the maximum ? So actually, we can never get to , out of a simple principle: you can’t gain entropy by passing through a varible. The source variable has maximum entropy of .
So in this case, we actually benefit from the opposite expansion. We know that , and it is agnostic to . Therefore, we can maximize entropy with a uniform on
Interestingly, this channel is able to preserve in communication the average number of bits kept untouched, unlike what we saw in the binary symmetric channel.
Symmetric Channels (extra)
Consider a more general form, where we have as a matrix
What can we say about the channel limits now?
Symmetric definition 🐧
Now, in the example above, we notice how the rows are permutations of each other, and so are the columns. We call this a symmetric channel. Intuitively, it means that the entropy of the output doesn’t depend on the input, but the distribution does.
If the rows are permutation and the column sums are equal, then it is weakly symmetric
Example of weakly symmetric D
Channel Capacity
We can find the channel capacity by performing the following standard derivation
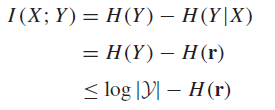
And we can maximize by feeding in a uniformly distributed input
Proof (factor)
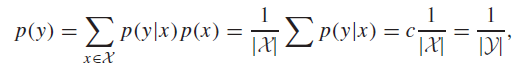
And this is true for weakly symmetric inputs as well