Math Tricks
| Tags | BasicsEE 276 |
|---|
Proof tips
- usually you can expand things twice, which gives you an automatic relationship (true for anything with the chain rule)
- use indicator variables as bernoulli RV’s
- upper bound probability of event . If you think of , does it entail event ? And does this event have an easily expressible form? If implies , then .
- always start from basic definitions; it helps a ton
The Basics
Notation
Sometime we use the notation if using another is confusing. This is common for CDF, or if the likelihood is a random varaible
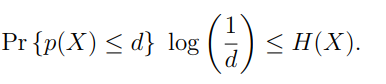
- we use CAPITAL to represent the random variable itself. So means a random variable such that we run it through the probability function after sampling
- general rule of thumb: if it’s outside of a summation, and you just want to refer to “something”, capital is the way to go.
- we use lowercase to represent a sample or an instance. So is a number (shows up in summations, etc).
Proof techniques
- To show that , you can show a few things. You can show that their differnce is positive / negative
- for differences: compute the first derivative to find the maximum difference or minimum difference. compute the second derivative to see how many extrema you need to test for
- the concavity argument: if at one point and at this point and for all , then you can say that for all after that one point of equality.
- dead end? Try something new!
- Always feel like you can justify from first principles.
- sometimes you need to go both ways: there are some facts you know directly from some inequality, and then you move your way backwards to get your final product. For example: you know that , and then you know that , so you can conclude that .
- Simple tricks work best for minimally constrained problems
- add and marginalize is a really big one too
- To show something about , you can use this: . Simple trick but the latter gets you to something that you might be able to calculate
Limit behavior
- . Intuitively, this is true because one pinches linearly and the other explodes logarithmically
- If you want to know what happens to as , you need to replace it with one variable (i.e. you need to find a relationship between . Two-variable limits are not totally well-defined unless this replacement is done.
- , and by symmetry we have
Summations
Raising a summation to an exponent is the same as nesting exponents. This goes to a deeper truth that
which is intuitively true because multiplication does pairwise, and nested sum also does pairwise.
Fractions
- The trick always yields , although that sometimes isn’t the best form. Always look for ways of simplifying that remove the extra 1.
CDF
If you have something like , this is an integral over the PDF. If you’re dealing with discrete things, just take the summation (discrete there’s no notion of PDF).
Expectations
- remember that expectation is an integral. You can’t switch any non-linear function with an expectation (although Jensen’s can give you an inequality)
- If are independent, then .
Marginalization
You can marginalize distributions, but you CAN’T marginalize something like . This is because we already take the joint expectation and the entropy operator is not linear.
- Instead of marginalizing, consider chain rule
But…marginalization is your most common tool. If you want to calculate some but it’s easier for you to calculate , then do .
Chain rule
It can be easy to forget the actual chain rule. Remember: . The variable only appears on the non-conditional ONCE. It does not appear again, or else we run into problems.
“p”
Here’s also a point of confusion that sounds stupid but it happens all the time. The is not a specific function. So isn’t the same as , etc. This is true even when the is specialized for some application. Probability is not a function.
Hard constraint inequality
If I have and I know that , what can I say about ? Well, I know that , and this is the tricky part: we know that , so . So, . The inquality is flipped. This is also true by vibes. A common mistake is the switch the location of the without flipping the sign of the inequality.
Advanced properties of RV’s
The formal definition of density
So for continuous RV’s , we have the notion of density . When defining the density, we always do it in terms of the CDF .
so this is a great first step when you’re dealing with proofs with density. And of course, remember that
and you can apply functions inside the , like .
Information lines vs dependency lines
In things like Markov chains, we draw things like . In communication, we might draw something like . What is the difference? Is there a difference?
- The indicates that there is something that messes the signal up between and . Depending on how bad it is, could range from 0 to some positive number.
- The is a more vague version of this notation. We just know that there is a dependency, a distribution . This could be the same as , although it is generally good practice to remove the arrow if that’s the case. So there’s a subtle difference. If , then we know that .
Densities
The density means the likelihood of , which ALSO means that if you were to select at random, the likelihood of being this current has likelihood .
Remember that is a value, as is scalar. Therefore, is well-defined, but NOT . The conditioning must always be deterministic. On the other hand, is totally fine; it’s just another random variable.
What is a random variable??
A random variable is nothing more than a tuple containing distribution, and a range . This in indexes into , but that’s only an indexing property. So…as long as you have some set and a valid probability distribution with the same cardinality, you’ve got yourself a random variable.
Example
As an example, we can have be the and as the . Note how and can have no relation. As long as they have the same cardinality, it is possible to make an RV out of them.
Convexity in a distribution
This is definition a mind trip, but certain things can have convexity or concavity WRT distributions. Don’t get too confused. A distribution is just a vector with L1 length 1. You can interpolate between two vectors, whose intermediate vectors are still L1 length 1. This interpolation is the secant line drawn between two distributions.
Linear function of a distribution
When we have something like , we say that this is a linear function of . Again, back to our view that a distribution is a vector. This is the same as doing a Hadamard product on the vector, which is linear.
Same RV, same parameters
Here’s a critical distinction. When we talk about some RV , it has an identity as well as parameters. If we set , this means that every sample of is the same as .
However, there’s also the notion of sufficient statistics. If we have , then we have the same distribution, but the identity of are not the same. As a consequence, if you draw a sample from X, it may not be the same as the sample from Y.
Distributions over likelihoods
So is a random variable, and is also a random variable. This is because is just a function that takes in something and outputs a number between 0 and 1. Therefore, is feeding the sample back into its own likelihood fuction. This is perfectly valid, and in fact, this is exactly what entropy does! .
Union and intersection bounds
This is basic stuff but it can be very useful
- “at least one”: use a union, which is upper bounded by the summation of probabilities and lower-bounded by the single largest probability
- “all of them”: use an intersection, which is upper-bounded by the smallest probability. For the lower bound is a bit tricky. . If , then we can make them maximally separate. If , then there must be some intersection. So
Remember that “not one” is equivalent to “all of them” (the laws of set negation).
Transforms of random
This is kinda tricky. If we have an invertible matrix and a uniform random vector , then is uniformly random. Why?
Well, if is uniform, think about the VECTOR not the scalars. This will map to in a one-to-one manner. So, the G is just reshuffling the random.
There are also special properties when we are in . Namely, adding random uniform vectors make more random uniform vectors because addition is equivalent to bit flipping. This is not true for real-valued vectors. Adding uniform RV’s is equivalent to a random walk, and there are some deeper theories about this.
- and as such, if you have any random uniform matrix and multiply it by some , then every output will be random, as every output is a different sum of random uniform columns.
Splitting and moving in entropy, MI, etc
- to split before conditional, consider using any chain rule
- to split after conditional, consider using mutual information, which breaks , which gives you essentially the “chain rule” but on the other side of the conditional
Making distributions from nothing at all
When you’re faced with something that feels very close to a distribution, feel free to multiply by the sum and divide by the sum. Division by the sum makes the thing into a distribution
Example
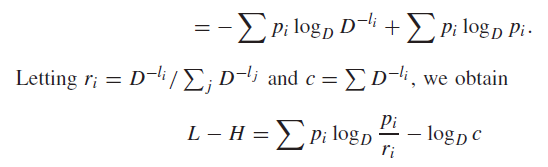
Some tips for spotting wannabe distributions
- summations with indices (just divide by the summation to get a distribution). Often, you can make the summation into an expectation of something WRT a distribution .
- things with logs and inequalities (because with a distribution, you can use Jensen’s inequality)
Why do this? Well, things like Jensen’s inequalty and expectations don’t work without a distribution, so it’s beneficial to make one.
Writing distributions as charts
- joint distribution: whole thing sums to 1
- Conditional distribution: column or row sums to 1
- computing conditional from joint: normalize across a column or row
It’s tricky keeping track of what is what sometimes! Good labeling is always key.
Martingale
A martingale is a stochastic process where the expected next state is the same as the previous state. Or, in mathematical terms
A good example of a Martingale is a random walk. This is a bit beyond our paygrade, but Martingales have certain interesting properties that we can use to our advantage.
Change of variables
Suppose that you have where is invertible and differentiable. You eventually want to integrate along , but perhaps the formula is simple in space. So you start in space. For the sake of this problem I’ll just be doing a simple integral.
Oh, but this is weird. How do we integrate over ? Well, we know that , so this just becomes
which hopefully is reminiscent of u-substitution. And then you just integrate over .
General strategy when dealing with change of variables: know how these are related on the non-derivative but also through the derivative so that you can connect them.
Finding f
In the derivation above, we just assume that existed naturally. Now, typically for distributions, you have some , some transform , and you might want to find the quanity , which is easier to do in y-space first, but that you require you to find some equivalent of density in Y-space. Now this is actually not trivial. You start from first principles:
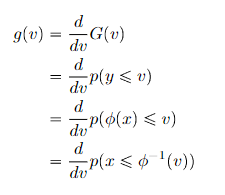
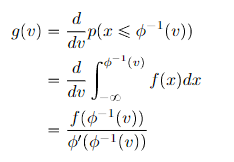
Note how you divide by this derivative term. This is a result of the density definition.