KL Divergence Deeper Look
| Tags | BasicsCS 228 |
|---|
KL Divergence
KL divergence is a more involved form of cross-entropy.
This means that intuitively, DKL is the "loss of encoding efficiency" you get after switching from to distributions. The more different the distributions are, the higher the DKL divergence.
DKL identities
We can prove that DKL is always non-negative. It requires a little trick of essentially multiplying by 1 and changing the expectation...
Proof


We can prove that DKL is 0 IFF the two distributions are identical (meaning that their PDF's are the same)
Proof



We can also prove that the DKL has a "chain rule", which is kinda obvious when you think about the log.
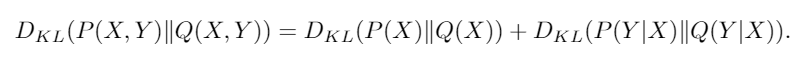
Proof

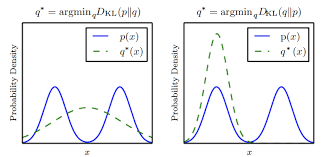
Observations about DKL
This section is purely supposed to be an intuition-based section that discusses what DKL actually does. For a more rigorous treatment, see my 228 notes.
For instructional purposes, say that we are fitting over distribution by minimizing ( more on this in 228)
Maximizing the entropy
The first component is , which is the negative entropy. By minimizing DKL, you are pushing to be as ehtropic as possible
Maximizing Log likelihood
The second component is , which means that you are maximizing the expected log likelihood of over a sample of .
Overall effect
This means that you find the mode of the distribution of and then you "fatten" the distribution out to fill as much of as possible.

Asymmetry of DKL
cares about matching the distribution of to . Fundamentally, it takes expectations across , so if you are dealing with a multi-modal distribution of , a minimized WRT a single-mode will pick a single mode of . However, if you tried minimizing , then you are sampling from . In this case, your best would be a large bump between the two modes of .