Joint Typical Sets and Optimal Coding
| Tags | EE 276Noise |
|---|
Vocabulary
- We have
- The is the
message
- The is the
input sequence. Individual are known ascodeword. We sometimes use to represent that there is an encoding process
Proof tips
- capacity is encoder agnostic, and with symmetrical channels, we know that the input sequence has to be uniform
Joint Typical Sets
So we have gotten us a nice property, a necessary condition of a noiseless encoder. However, we have made little progress on how we actually construct such a thing. In our discussion on compression, we essentially started with the concept of a typical set, and from that typical set came the primitive compression strategy. Let’s try a similar workup here.
We need the concept of a joint typical set because we have a set of inputs and a set of outputs to the coding channel.
The Joint Typical Set Definition 🐧
A sequence is jointly typical if three conditions are met
- is typical
- is typical
- The equation below
- We need the first two conditions because otherwise, we can just have some very large number times some small number to yield a product within that bound. If is typical, we automatically constrain what is.
- Furthermore, even if X, Y|X is typical, you can perturb things enough such that the marginalized Y is not typical. So that’s why you need the additional Y constraint.
We arrived at this notion of bounding . This has a special meaning: let’s formalize this idea of conditional typical set:
This means that every output has a set of that is “most expected” to cause this output.
Understanding the relationship
- There is a large set of typical X and a large set of typical Y of sizes .
- There is a set of X, Y whose joint probability is squeezed within .
- there may be elements in this set that is not typical on marginal with X, Y (sometimes both)
- You can imagine that at large numbers, these occurrences are rare.
- There are select tuples of such that we form a joint typical set of size .
- in this case, we impose the constraint that X, Y must be typical. In this case, the third point provides the constraint for the . The size of this true joint tyipcal set is less than
- For every X, there is a set of typical Y of size . These X’s don’t have to be typical themselves
- For every Y there is a set of typical X of size
Here is a good visualization.
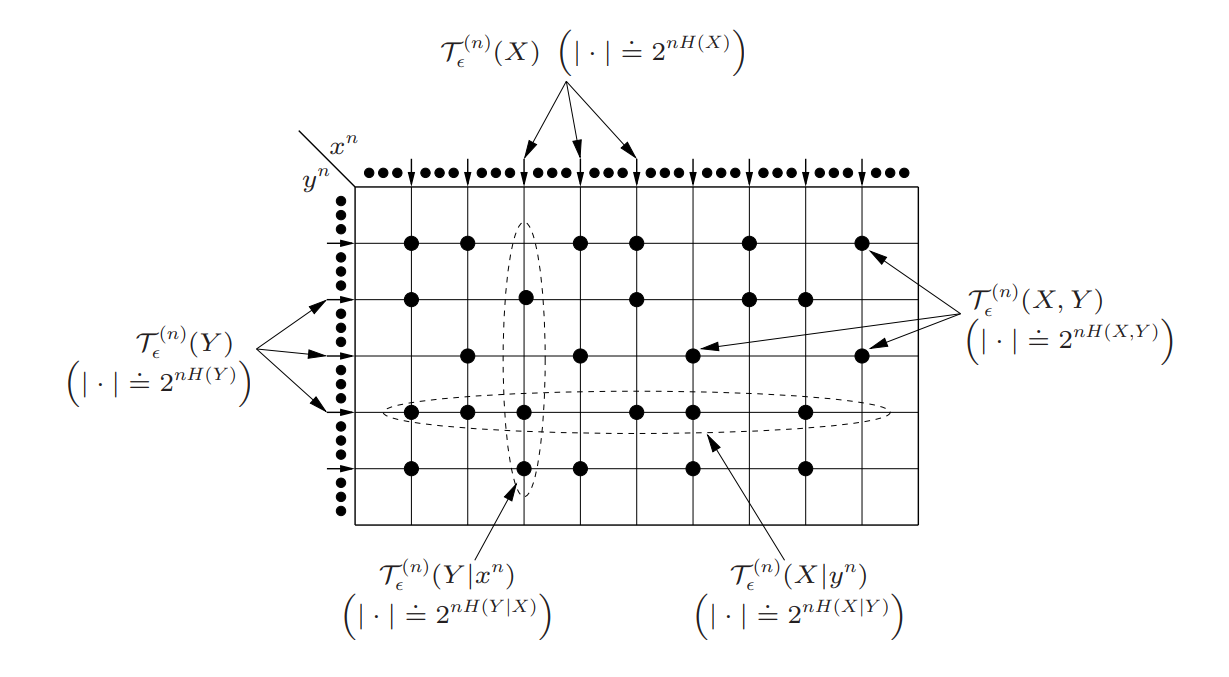
Properties of Joint typical Set
-
Proof
We know that all , converge to the entropy in probability, as well as due to the law of large numbers and the AEP. Therefore, intuitively, the union of the set of things that don’t satisfy the jointly typical set will get smaller and smaller.
-
Proof
Same as the proof for the singular typical set bound
-
Proof
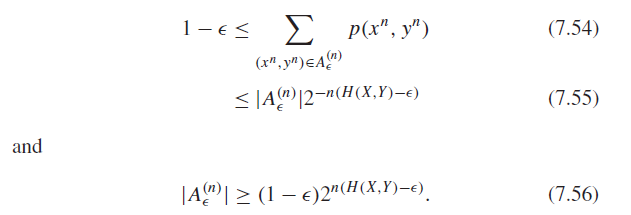
The argument is actually very nuanced because there are X, Y that are not typical. We bypass this by using the AEP on the joint.
As a back-of-the envelope calculation, at very large N, everything will be typical. The size of typical set of X is , and the size of the conditional typical set is . If we assume that we can satisfy the Y typicality just because it’s far more likely to be tyipcal with Y at large N, then we can just multiply these together to get .
- If we let and (i.e. marginalize and pretend tnat X and Y are independent), then and for large enough , we have
Proof
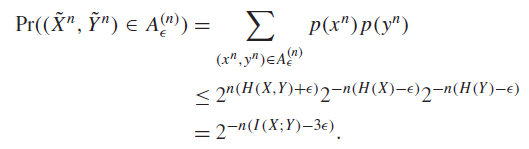
This is true because 1) the inside probabilities are bounded because of the marginal restrictions on the typical set and 2) the size of the A is bounded.
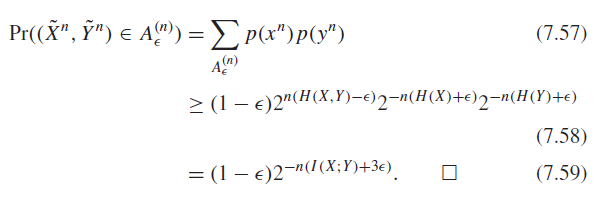
Similar reason as above.
We care about this last property because it basically says that the probability that a randomly chosen pair from the marginals is jointly typical is about . A signal is unique if the pair is in the jointly typical set. There may be other confounding interpretations, but if it’s outside this typical set, then these get asymptotically smaller as gets large.
This indicates that there are distinguishable signals.
Channel Coding Theorem
The Setup 🐧
Let’s review some terms introduced in the previous section. We have , the channel capacity. We have , the rate measured in bits code per bit of channel. We have , which is the number of bits in the message The diagram looks like this:
The number of bits in is just .
Sometimes, we denote the code as which shows how this W is encoded through some sort of encoding (not compression; that’s done before W).
We assume that the channel is discrete and memoryless, which means that . This does not imply that all is independent. We do know that is IID uniform, but the coding algorithm may not choose to keep that IID uniform.
The Coding Theorem ⭐
We assert that if , then the probability of error becomes arbitrarily small with a smart choice of code. It is not true for any code.
To prove this, we will first actually show that any randomly chosen code will yield a probability of error that gets arbitrarily small.
Why we care
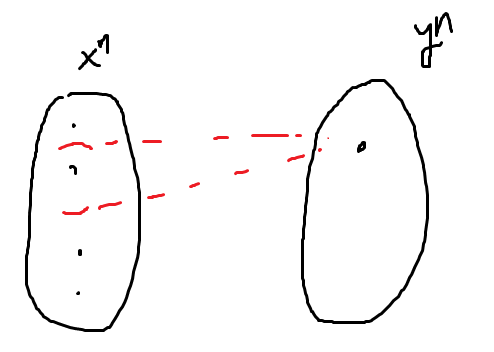
So essentially, we want to show that there exists some coding scheme (denoted as dots in the oval) where we can cleanly infer the input given an output . This is non-trivial. The red parenthetical is the jointly typical set given this , and there are quite a few.
The proof
We start by making an important assumption: we only deal with typical sets of , because as gets large enough, all sequences become close to typical.
So let’s start with a randomly generated code. In other words, we start by generating a bunch of random and binding them to . Why? Well, the would be uniform, and if we have a symmetric channel (our assumption), then we would be at capacity. Our limit of R is based on the fact that the P(x) hits capacity.
If the channel is symmetric, then the will be uniform and every is the typical set. This is the easiest to work with. If the channel is not symmetric, you will use the optimizing distribution . This is slightly more complicated. For now, assume that every code we bind will be in the typical set of .
Now, the true will be in the conditional typical set with high likelihood (by the AEP), so we don’t have to worry about that. Instead, we are concerned about some other being in the region of the conditional typical set of , which would be a problem. Why? Well, then there’s ambiguity in the decoding!
But here’s where the random code selection comes in clutch. From the AEP properties, we know that there is around elements in the conditional, and in the total typical of . Therefore, the probability that another code lands in the conditional is just
So this is the probability of a single being in the conditional. What about all of the ? Well, we can easily set up a union bound
For context, remember that there are different ’s. And the last inequality is where we use our original claim that . The final equality comes from the assumption that the distribution of is chosen to meet the capacity.
From here, it becomes obvious. As , the pinches down to 0. And the slower you send, the faster the error rate drops.
And finally, we need to make one final conclusion. As this error probability is averaged over the randomness over the channel AND random code (implicitly; all random codes have the same bound), we can use the law of averages to say that there must exist at least one code that does better than the average random code, so we are done.
Proof (more rigorous, different approach)
To actually prove this, we need to establish what an error is. An error can happen in two ways
- The true code is not in the typical set of
- There are other imposter codes that are in the typical set of .
Now, let’s formalize this. Define event as the following:
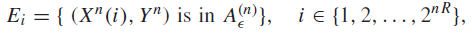
Error 1) happens when isn’t true at the correct . Error 2) happens when at least one other is true at the incorrect . Using the symmetry of codes, we can just assume that we are coding . This yields the following
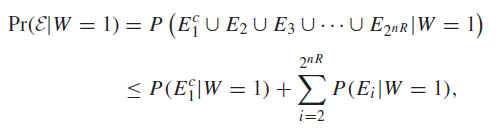
Now, we know from the AEP that the first term becomes smaller than for large enough . From property #4 of the AEP, we know a bound on two sequences being in the typical set. This yields the following workup
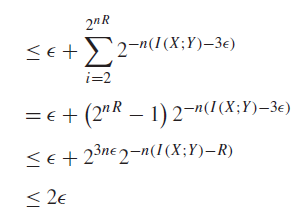
And so we have shown that the probability of error pinches down to zero!
The Bound on Communication
The communication limit 🚀
Here’s the a key theorem: if , then is large, where is the error probability in transmission.
We will now prove this theorem by finding a lower bound on . We see that in certain circumstances, the lower bound is zero. These are the times when it is possible to have an error-free code.
Proof: starting with Fano’s Inequality
Now, this is very lofty, because it seems like is very hard to quantity. However, let’s think for a second. The error probability sort of maps to the entropy of the decoding, given the input, right? Or, in other words, . If we want to have an arbitrarily small probability of error, this conditional entropy should be near zero. Otherwise, it means that there is some uncertainty about the original message given the output of the channel.
Now indeed, as we remember from Fano’s inequality, we know that
where is just the size of the input, so . (to review, look at the notes on Fano’s inequality).
Moving towards the bound
Lets’ just consider . We know that , which means that
Now, because W is IID uniform, we know that , which means that
Intuitively, this makes sense. The entropy adds noise, and the correlation between the input and the output can reduce some of that noise, but only to a certain point.
Now, because , we can use the data processing inequality to state that . Therefore, we have
Let’s continue. We can factor the mutual information into . Now, the second term is very easy because of the discrete memoryless channel assumption. . The first term isn’t actually easy to compute, but we can bound it on independence. From this, we have .
Putting this together, we have
This last term depends on the channel properties as well as the distribution . However, we know a bound on this! It’s just . So .
Putting this together, we have
Already, we are starting to see that if , then the lower bound is non-zero, which is bad.
The final move, we just plug into Fano:
asymptotically. And this is exactly what we are looking for! If , then the lower bound is non-zero, which means that the probability of error must be greater than this non-zero value.
Slight caveat on the bound
So this is based on the possiblity that is reached. The more general result is
Because sometimes you might be artificially limited somehow to a class of that doesn’t achieve optimality. So the lesson: your can’t exceed the CURRENT mutual information.
Simple case: zero-error codes
We can show the converse directly (without the contrapositive) if we know that the error probability is zero. The key here is that if , then necessairly, we have .
Then, we have
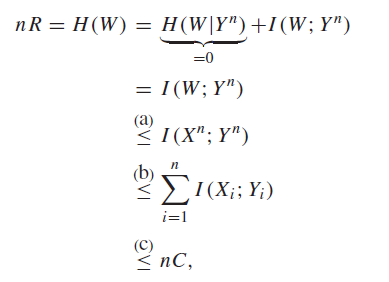
(a) is data processing inequality, (b) is independence bounding (see above), and (c) is predefined channel coding limit.
This is just the stripped down version of the proof above. In the proof above, we had to give a lower bound on , and showed that this lower bound is only zero in certain cases.
Rates and Distributions
This is where I explain something a bit confusing.
So there’s this idea of an optimal distribution that reaches . In binary symmetric channels, this is always uniform. But you shouldn’t assume that it’s uniform all the time. Because sometimes you might need to compromise, etc.
There’s this idea of an input distribution , which we assume a priori that it is IID and uniform. So the message is uniform.
There’s this idea of an encoder which takes and transforms it into . This can and will entangle the individual bits, so is no longer IID. That doesn’t matter. As long as the individual marginals fit the , we are still at capacity.
So where does the rate come in? Well, you can always decide how much information you cram into , i.e. how large your is. We don’t care how this is constructed just yet; we imagine that we can adjust it for different size . The ratio of your size to the size of is your rate.
Now, if we assume that our can output distributed like , then the rate is restricted as .
But what if that’s not the case? Well, then the rate limit changes. In the derivation of the Channel Coding theorem and the converse, we always bound and use to replace the . Suppose that there is some tighter bound due to some other constraint. It might be that your isn’t expressive enough, or you need to share a channel with something else, etc. In this case, you must replace the bound with this value.
Channel definition
You can define an arbitrary channel through the mutual information. You might have , which means that you send out one signal and you try to decode it by looking at two outputs. Every mutual information can yield a channel!