Compression Algorithms
| Tags | CodingEE 276 |
|---|
Huffman Codes
The algorithm is pretty straightforward.
- Pick the two least likely variable outcomes and make them into a leaf node. One of them gets 1, the other gets 0.
- Combine the likelihoods of these outcomes into a super variable and add that back into the pile for consideration.
- Keep doing this until you run out of things to code. The tree you create is the huffman tree and the coding is optimal
Deriving the Huffman code
We can make this algorithm from first principles, where we just have access to individual probabilities which we sort in order . We know that the lengths must go the other way: . Otherwise, you can just swap two lengths and we will get a shorter expected code length.
Furthermore, as we will be dealing with binary codes, we know that . If this isn’t the case, say , then we know that doesn’t have a sibling, which means that it can be “rotated” to form a shorter tree.
Finally, we know that (again, because this is binary). So it makes sense to start thinking recursively. We can make and share a common parent node. This parent node has length . We dopn’t know these numbers yet, but we can rewrit4e our objective:
which we can refactor into
and this just looks like the old form with one fewer term! (because the term outside of the parenthesis doesn’t matter)
The constraint is
which again collapses down into the familiar form.
Huffman code analysis
The complexity of the Huffman code is wholly the sorting operation which takes place after every run. It takes to sort initially, and to insert the new value. So, overall it’s , where is the size of the alphabet.
Ultimately, Huffman does a good job, but it’s not using a lot of information. It only uses the distribution of each character and encodes it separately. Longer sequences might have better structures to exploit, but because of the complexity depending on the alphabet size, we can’t just “chunk” together RV’s to form an alphabet size (or else we risk blowing up the complexity).
Arithmetic Codes
Huffman codes are elegant, but they aren’t good at encoding long sequences (i.e. it makes the inductive assumption that everything is IID, and will encode single characters. Arithmetic codes are designed to encode long sequences with linear complexity, although the range of encoding is more limited.
The tl;dr is that arithmetic codes turn the code into binary decimal representation, which yields some very nice properties
Arithmetic Code setup
Let’s suppose that you had IID that are sampled from some alphabet with size . Your goal is to encode them into as optimally as possible. This means that the must be distributed uniformly (or else we can run through the encoder again and get something even better, etc.
The goal of an arithmetic code is to find a function that maps between (multinomial distribution) to a uniform distribution.
Binary Decimal Representation
The trick here is to turn the list of RV’s into numbers. How? Well, we can consider binary decimals: and We assume that these are infinite-precision decimals (and we’ll explain why).
The is some sort of distribution expressed in base .
The is a uniform distribution, because every is taken uniformly for maximal entropy.
Why do we use this setup? Well, there are a few nice properties
- It is possible to create an invertible mapping (see below)
- when you add more data, like , it doesn’t require you to recompute any of the previously sent bits; adding more data to the beginning just means adding more data to the end.
- why? Well, when you have , you are bounding the outcome between and (think about it: we are asuming an infinite decimal). Adding another decimal place will only shorten this bound.
- the CDF can be computed recursively (see below)
The Mapping Function
So you just need to find some function that maps the binary-decimal representation to the binary decimal representation. To do this, we start with the simplest constraint: . This is only true for uniform distributions. This yields , and we know that the left hand side is just , the CDF. So we have
and a natural choice for is
Is this well-defined? Well, we know that is monotonically increasing. We also know that every possible sequence of characters have a non-zero probability, which means that is always increasing and therefore invertible. And we showed int he last section that this has some really nice properties that make it easy to compute
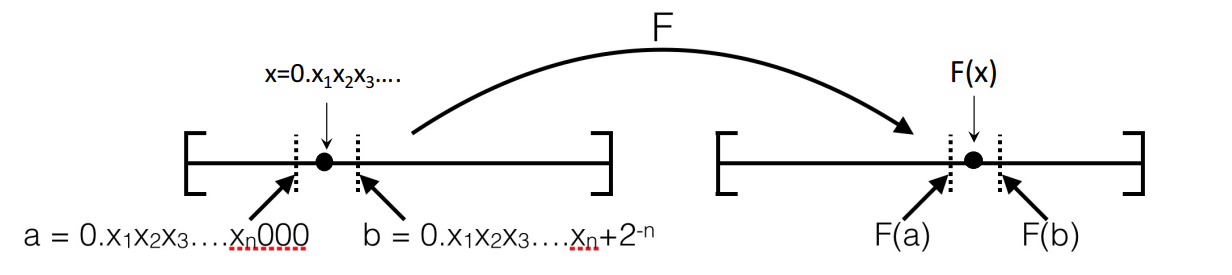
Computing the Mapping Function (CDF)
We can compute the cumulative function recursively
The first term you have by previously getting , and the second term is just a CDF function of . The second term can often be factored by the probability structure and computed directly.
For the upper bound, we realize that is just a marginalization across all , which is equivalent to doing .
The actual coding
The actual coding is surprisingly easy.
- Turn any sequence into a number (expressed in base ).
- Create lower bounds and upper bounds
- Recursively compute and using our CDF formula
- On the new number line in space, consider . Take the middle of the bounds, and use the entropy limit to decide the number of decimal places to send
- The middle of the bounds is arbitrary. Any number inside these bounds will map to the right number in the space.
The actual decoding
So this is pretty interesting. Here’s something interesting. When you’re dealing with an unknown bit, you can split it into two intervals: and . If you compute this, it’s a clean split. But if you’re in one interval, you know what the next bit will be!
The second realization is that these intervals map very cleanly into the space. You should convince yourself that it maps the clean 50/50 split into a (1-p) / p split. This makes sense, actually. The algorithm is therefore
- Split the intervals
- map the intervals to U space
- look at your current expansion . This forms an interval . If this interval is firmly in one of the intervals created in step 2, then you know what bit should go next in the data. Else, add more until we are firmly in an interval.
- Rinse, repeat.
Lempel-Ziv Coding
The idea is actually stupidly simple. Given a string, find out how to express the next characters using a substring that has been previously expressed.
Sliding Window LZ Algorithm
If is your window size and you’ve compressed up to , then the next compression move is to find some such that for all , where is the largest possible. You denote this compression with two possible tuples: is when you specify the start point and the length of the match . is when you can’t find anything and need to specify an uncompressed character (usually close to the beginning). The is a flag bit that tells us what type of tuple we’re looking for.
Concretely, this is the algorithm
- Start with a sliding window that looks backward
- For the current position, see if you can find a non-trivial substring in the previous window. If you can, mark where it starts and the length
- if you can’t, just encode one character
- Slide the window forward steps until the previously encoded string is now in the window
To decode, you just construct the code. Because the code will only depend on things in the past, it is trivial to construct
Proof of optimality
Here’s the general sketch: as (the size of the coding chunk) as long as the window stays large enough, the probability of including a typical set in approaches 1. Why is this important? Well, it just means that we are arbitrarily likely to find what we need in .
The proof
First: we bound the probability of some typical sequence not happening in W

Next: we use a union bound on the probability of at least one element in typical set not appearing
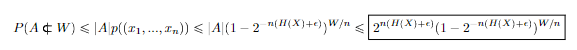
Next, we establish the following relationship between and :
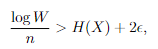
And you can show that the probability of at least one element not appearing will pinch to 0 (this is an algebraic slog, so I omitted it).
Finally, we can see two properties
- is the average bits per message character, and we know that this gets close to . This shows the optimality. Why? Well, is needed to specify the location of the found string in the window.
- We don’t need to worry about the length of the code , because you need bits for that, and .
Tree-Structured LZ Algorithm
We parse the source sequence into the shortest strings that have not appeared so far. So this means that you’ll be building up longer and longer strings. And more specifically, for every element in this sequence, its prefixes must have all occurred earlier. More specifically, if you cut off the last character of the string, this shortened string must have occurred before, or else we wouldn’t have encountered this current element.
Therefore, we can send the parsed strings by giving the location of the prefix and the value of the last symbol. More on this later
Which coding algorithm should I use?
When coding, you need to consider three potentially relevant steps
- Learn statistics of the coding data
- Construct code
- Use the code to encode the data
So let’s compare the three previous methods
- Huffman code is a very elegant approach, but it requires all three steps and is exponential in the number of bits to encode (we need multiple bit encoding, as often the closeness to optimality is asymptotic in bit length).
- Arithmetic code skips step 2, and can construct the code using only the statistics. It is also linear in the bit length
- Lempel-Ziv skips steps 1 and 2 and encodes directly from the data
All are asymptotically optimal.