Asymptotic Equipartition Property
| Tags | CodingEE 276 |
|---|
Proof tips
- typical sequences is bounded individually in probability. We also know that probabilities are bounded in summation, so we can use these two bounds to our advantage
- Notation: or means , etc.
Sending Codes
So let’s formalize the problem of code-sending and establish why we care. You want to send a message that you don’t know (not pre-determined) across a channel. For now, let’s assume that the channel has no noise. Can we send with as little number of bits as possible?
We model the code as a string of random variables. The parameters of the random variables are determined by the source (think of each random variable as a character, etc). Depending on the properties of the random variable string, you may find some neat properties.
In reality, the RV’s are dependent on each other through the markov property with potentially a long history (think natural language). However, we may, as a simplification, think of them as IID. This section shows some critical theory under this IID assumption. How can you best compress a string of samples?
AEP Theorem 🚀
It is similar to the law of large numbers. The law of large numbers says that the average of samples is close to the expectation of an RV. The AEP states that you can approximate the by taking samples and computing .
Formally, if we have IID from some distribution , then
Or, more formally, for every , there exists some such that for all , we have
You can understand that this is a random variable where you sample something and feed that right back into its own distribution. So it follows from the law of large numbers that the AEP is true.
Generalized AEP
We will talk about entropy rates later, but you can essentially say the same thing about , where is the entropy rate. In other words:
Understanding AEP
To truly understand the AEP, let’s look at an example with bernoulli with probability . In this IID sequence, permutation doesn’t matter. It only matters the number of ones in the sequence. Recall that .
Now, if you plug this into the AEP, you can say that
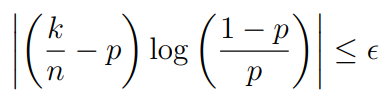
which is equivalent to
which should remind you a lot of the law of large numbers. Just set and you’re done. This gets you a bound for every sequence of terms that are in the AEP. Because the AEP has , it means that for any , we can show that any sampled sequence has is within an epsilon sphere with confidence
When does this break down? It breaks down when and . In this case, there is no bound on . This makes sense as the probability no longer depends on if .
Typical Sets 🐧
We define the typical set as the set of sequences drawn IID from , where
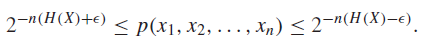
Don’t try to think about why these bounds exist; as we will see, they exist only so we have some nice properties.
Intuitively, the typical set is just the set of sequences that are the least surprising. A typical set may be a small subset of all set of sequences, but as we will see below, an element sampled from the random variable is highly likely to be one of the typical set elements.
As a non-probability version equivalent, you might consider the set of samples whose mean is within an epsilon-ball of the true mean. This is a typical set for estimating sample means. If you’re ever confused, think of means instead of entropy, and all of the properties should be intuitive.
Properties of Typical Sets
- For all sequences inside a typical set, we have . for any and large enough . In other words, inside the typical set, our estimated entropy is within an epsilon-ball of the true entropy. Proof through Typical Sets definition.
- The probability that a sequence belongs in the Typical Set approaches 1: for a sufficiently large .
Proof (Using AEP)
By the delta-epsilon definition of AEP, we have that
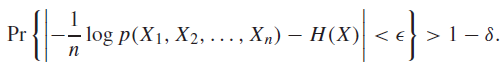
which is true for all sequences of random variables. Now, we observe that when this log-prob is inside the epsilon ball of , it ALSO corresponds to being in the typical set. Therefore, we just need to set and we are done.
- There is an upper bound to the number of elements in the typical set: .
Proof (definitions)
This should be pretty obvious. The probabilities of each element in the typical set is upper bounded
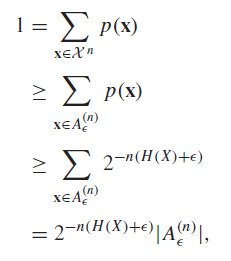
which you can easily solve.
- There is a lower bound to the number of elements in the typical set: .
Proof (using property #2)
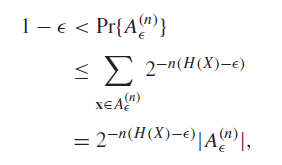
The variance in probability increases with due to the term. This is actually pretty intersting!
Data Compression with AEP
So here’s the big point of talking about AEP. It seems weird to be able to compress things of size into their entropy on expectation, because it feels like we are shoving too much data in too little space. Information theory focuses on how compression is possible. By showing that a Typical Set expands to become -close to the full probability mass, and by the knowledge that the Typical set is bounded by size, then we know for certain that we can indeed encode with bits per character.
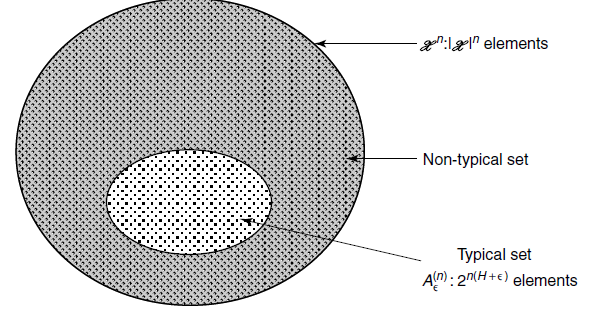
Naive Compression
Naive compression assigns an index to every possible sequence, which has size . We can rewrite this as , which means that it takes bits per sample. Can we do better?
Using Typical Sets
Because there are at most elements in the typical set, we can describe it with bits, which means that we only use bits per sample.
Now, interestingly, if the distribution of is uniform, then , so the typical set is everything, and all encoding is equally inefficient. So this establishes, through theory, what we mean by compression.
Optimal Coding theorem 🚀
Let represent an n-length sequence. There exists an invertible code such that
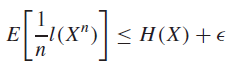
Proof (properties of Typical Set)
The key insight is that with large enough , the probability of being in the Typical Set is for any . We can set up the derivation like so
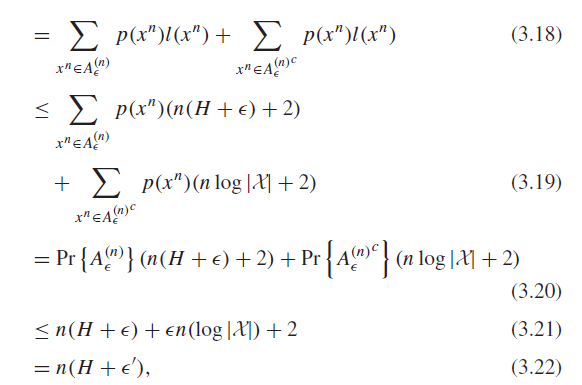
And this is sufficient (just let the original be such that is the in the theorem (classic analysis trick)
So the tl;dr is that on average, we can represent sequences with bits on average! But how can we actually do this? Well, we’ll find out the concrete coding schemes in the next set of notes.
Ultimately, why shall we care?
We have established a theoretical possibility of coding. And in fact, we can technically have a primitive proof-of-concept code in which we assign a code of length to sequences inside the typical set, and kept all other sequences as-is. In this case, we have shown that the compression length is asymptotically.
But this is super primitive and has problems.
In later sections, we will show how prefix codes can reach this theoretical possibility, to within one bit.
High Probability Sets
We define a high probability set as as the set such that . In other words, the probability of being in this set is larger than .
We can construct greedily by taking the most likely sequences first. As it turns out, has at least elements, which is in an order of exponent of , which is the size of .
The takeaway is that the highest likelihood sequences (high probability sets) have intersections with the typical set.
High Probability vs Typical sets
The tl;dr is that B is limited as a set (to the likelihood), while A is limited per value (by being within the right range). You can’t say much about , but is related to through some simple properties.
The high probability set is subtly different from a typical set. If we construct the smallest possible high probability set in a bernoulli sequence with , you will definitely see the sequence where everything is 1. However, the typical set may not contain that. The typical set contains samples whose probabilities are closest to the empirical entropy, which may not include the highest possible likelihood (because that may not be surprising enough!)
However, we do know from basic probability that for and (true for large enough numbers), we have
which means that there is a large intersection between the high probability and typical sets.
We also know that the smallest possible is upper bounded by the size of at large enough , as the set gets close to the full set, while the smallest possible is upper bounded by .