Applications
| Tags | EE 276 |
|---|
Distributed Compression
Say that you had correlated with entropies . Say that you want to send both of them to a receiver. We can, of course, just use channels with rates . But given that X, Y are correlated, can we do better?
So this is actually a hard problem because the encoders for X, Y don’t have access to each other.
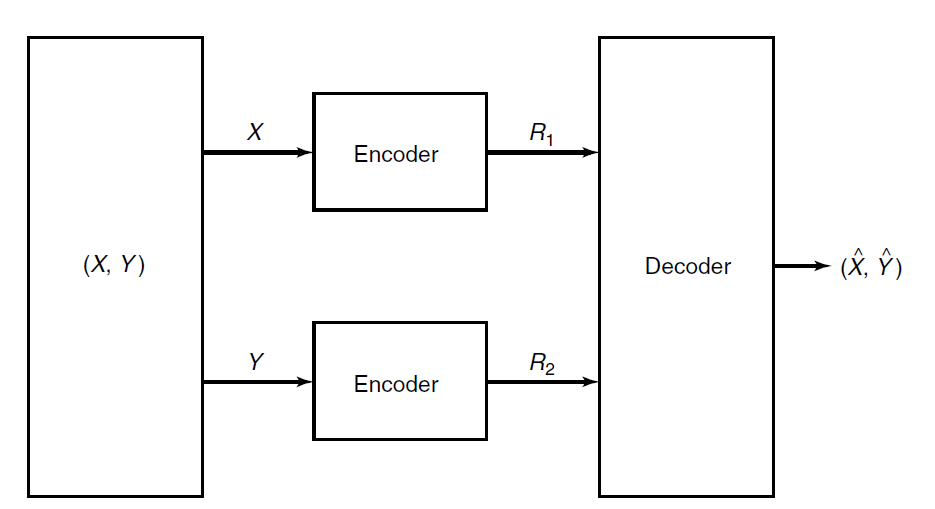
Toy motivation
Say the encoder and decoder had access to . Then, you can send at a rate , which is more efficient.
However, this is a pipe dream because we don’t have real access to during encoding. But now, we know that there is an interval , and the optimal coding rate lies in there.
Slepian & Wolf (Distributed Compression)
In this setup, we assume that the decoder has access to the sent Y, and that this has no errors. We can essentially use a glorified hash function. We compress by using a hash function, and then we use a notion of joint typicality at the decoder to infer, among all the hash collisions, which is most likely.
The algorithm
Let’s assume that we have pure access to at the decoder. This means that we need . If this is satisfied, then we do the following
- Pick a hash function with values, where we pick later
- Hash and deliver the bin index to the decoder
- Using the decoder, look at the indexed bin and find the element that is in the typical set of ( we assume access to this distribution). If we can find a unique result, return it. Else, return failure.
- Concretely, we look at the typical sets of , and there are bins, so every bin has typical sequences of . This actually can form a grid where one axis is bin and the second axis is the bin index. The area is just . The grid is uniformly distributed because it’s a typical set.
- Without knowing the bin index, this is a really bad situation because you have options from the typical set.
- Without knowing , this is a really bad situation because you have options.
- But what if you know both the bin index and Y? Well, here’s the interesting part. There are options and there are bins. So in expectation, there is only one option per bin. There is only one option that satisfies both and the bin index. This is why decoding is possible!
The formal proof
We can show that the probability of error is arbitrarily small by using three possible errors and the union bound. 1) received not jointly typical. 2) received X is a collision with another element in the typical set. 3) received Y is a collision with another element in the typical set.
All of these are bounded. The first error is just AEP joint error. The second error we can calculate
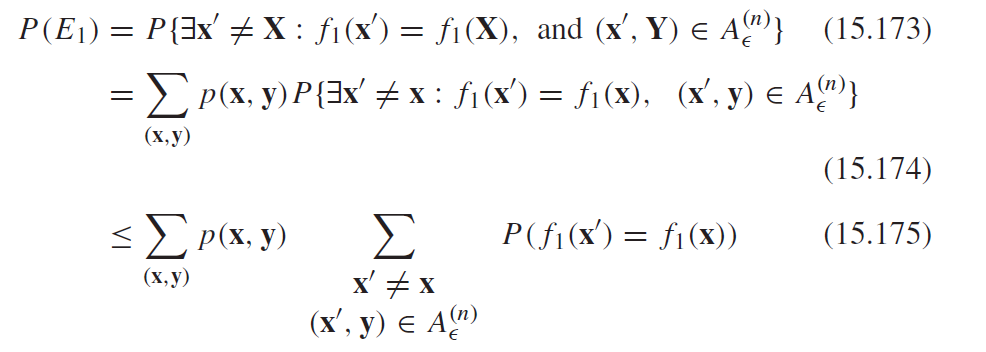
Now, this probability is just uniform and just because of the random hash. So we have
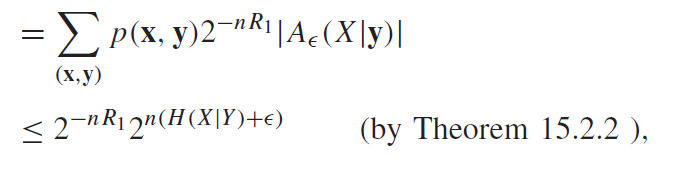
And here, we see that as long as , the error goes to 0.
Picking
So we can show that this algorithm works if . There are typical sequences per , Therefore, there should be bins. This is very handwavy, and indeed you can’t do any strong guarentees. You essentially want all your hash collisions to be with non-typical sequences, but you can’t guarentee it.
How good can this algorithm get?
So we can actually establish three critical restrictions that tells us how good we can actually get.
- If the encoder for X were given Y, then it transmits with rate
- If the encoder for Y were given X, then it transmits with rate
- If the encoder worked with jointly, then it transmits with a rate
We know that the corner point is , which means that the third restriction is actually meaningful. At the end of the day you get the following rate region for this encoding approach:
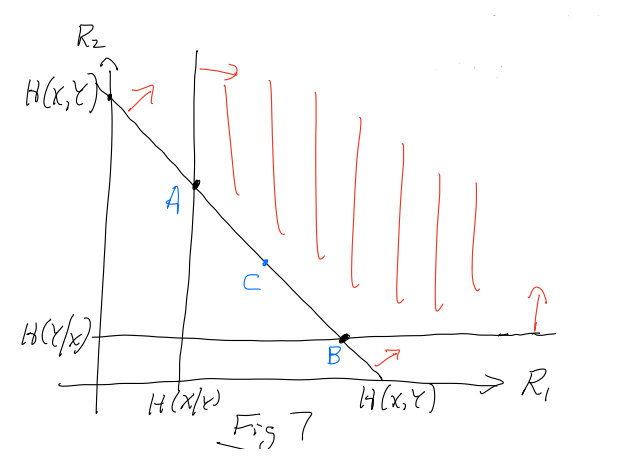
Now, it is possible to achieve point if we transmit at full rate and at the restricted rate given the hash function. Now, recall that this isn’t the same as giving directly to the X encoder. Rather, we showed that the hash function approach can yield the same rate lower bound!
It is possible to achieve point if we transmit X at full rate and Y at the restricted rate.
Now, we can achieve any point on the connecting line by just transmitting using the two strategies with varying probabilities. In other words, you might have two types of encoder structures created and during transmission, you flip a weighted coin.
Cybersecurity
In cybersecurity, you want to send where is assumed visible. Now you want to have . How can this be done?
Well, you might have a secret key and the code comes from .
Coding theorem
Shannon stated that to have perfect secrecy, you need . To achieve this, it’s actually quite trivial. Take as IID and do XOR. If you xor any this way, you will get as also IID (because you randomly bit flip; it doesn’t matter where you come from). And the receiver just need to do XOR the again.
Proof of the coding theorem

Next, we want to show that
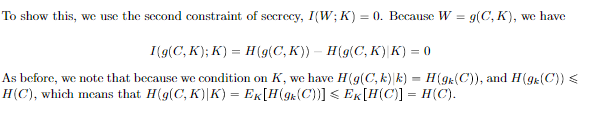
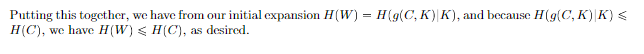
Can we extract this without sending it?
Common Randomness
So in an ideal world, if we have some correlated , can we extract some meaningful random that is shared the two sides? Intuitively, we can. If there is correlation, there is shared randomness between , as measured by , which we can try to extract.
So this sounds trivial at first: what if we just combined and generated a random ? So that would work perfectly, but this would be a security risk. Remember that represents a security key and that Eve can look at any sort of communication. To produce this , you would need to share across this channel. So you can assume that Eve can construct too, which would make your code meaningless.
So here’s the revised problem statement:
- You are given two correlated data streams . One is sent to Alice, and one is sent to Bob. Don’t worry about how these streams are created.
- You can communicate some message across a public channel
- You want to create a shared random key that both parties will share in common with high probability
- You want the message to give away as little of as possible
The common randomness solution
So here’s the thought process: if we can get to Bob in a convoluted way and have Bob use his knowledge of to decode , then we can use the remaining randomness of as the shared key. Why? Well in this ideal situation, both Bob and Alice have copies of . If they can systematically know what part of they reveal in the public channel, they can both peel back this known randomness to expose a secret core. They do this independently and require no communication.
All of this sounds fine, but how exactly do we accomplish such a task? Well, recall the Sleppian Wolf encoder. Let Bob be the decoder and Alice be the transmitter of .
If we assume that the Y encoder is perfect, then the Alice only needs to send at rate to convey to Bob. Now, to the outside observer, the rate is not possible for a noiseless reconstruction.
Concretely, recall that the SW encoder uses a hash function that pushes every into a bin . Inside this bin, we give this an index . So this can be described perfectly by . To send this at the rate , we only send the bin index , as where are of them.
On Bob’s side, the gives him the right bin to look at. Furthermore, he knows what is. So from our previous discussion about Slepian-Wolf, we know that Bob can decode with high probability. So now bob has and alice has . Both of them know the hash function, so it’s trivial to derive the part of the that wasn’t transmitted. Let .
What is the entropy of ? Well, recall the grid of size . It is uniformly distributed. So any slice is also uniform. The size of the slice is . So the entropy is jut . This makes intuitive sense! We were able to transmit bits of shared randomness.
Proof of optimality
So is this the best we can do? It turns out, Yes. Let’s proof it by using the converse. We will assert that .
Let be the code that alice gets, and be the code that bob gets. We have , so we have . Why? Well, .
Now, let’s condition on the message. Because , we can say that
Now, we use something tricky. Recall that are correlated. So we can construct the markov chain . Note that both determine , but we already condition the MI on the . By the data processing inequality we have . We’re in the homestretch!
Let’s use the chain rule to yield . Given that is a deterministic function of , we have . Therefore, we have .
To recap:
as desired.