The Key Distributions
| Tags | CS 234CS 285Reviewed 2024 |
|---|
Trajectory distributions
As shown in the previous section, there is the concept of a trajectory distribution, which is literally the distribution of a rollout tuple . With the dynamics and the policy, it is a directed bayesian model with factorization
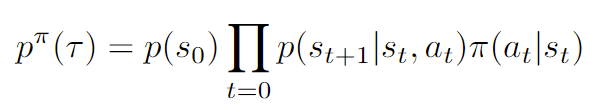
represented typically by . This is just a factorization using the chain rule and the MDP. Note that is dependent on .
State marginals
We can marginalize out all the states except for one to get . Because this is a factorable graph, we can use the variable elimination algorithm and complete it in polynomial time.
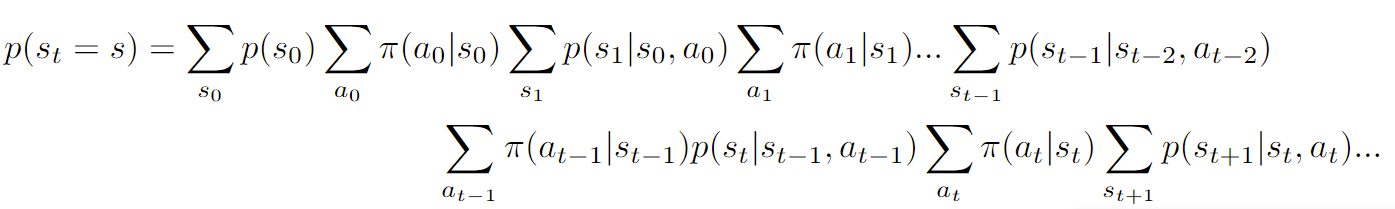
State marginals are stationary in infinite horizon
We can also arrive at the state marginals under the knowledge that for an MDP, the state marginal is the stationary distribution as . Same with state-action marginals.
Discounted Stationary Distribution
We can define the discounted state distribution as the following:
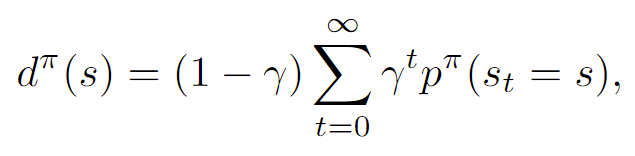
At first this seems a little weird, but intuitively, it weighs the state likelihoods by how late they show up (i.e. how much we should care). We care about this because it shows up in quite a few expressions.
We can also write this recursively:
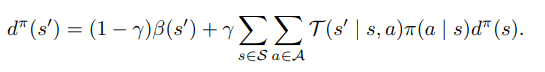
where is the starting distribution. This should look suspiciously like a value function recursion, which brings us to why we even use a discounted stationary distribution
Why care about Discounted Stationary distribution?
Actually, there’s a pretty neat identity that is useful. So if we let
then , where is the vector of all rewards for . Think about this for a second. By the definition of , it should be apparent where it comes from.
Stationary Distribution Identity ⭐🚀
This following identity essentially shows a relationship between an expectation across trajectories to an expectation across discounted stationary distributions
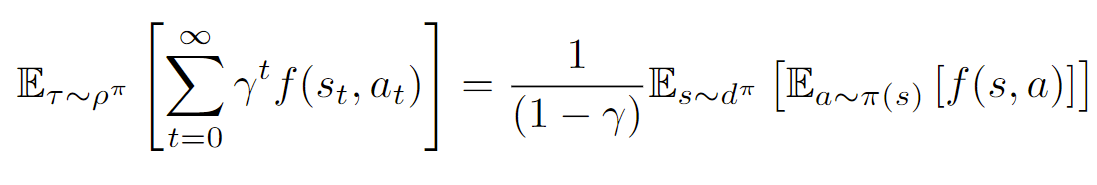
Proof (linearity of expectation, marginalization)
