RL Introduction
| Tags | CS 285 |
|---|
RL Algorithms: A quick survey
There are three basic parts of an RL algorithm
- Generate samples in the environment
- Fit a model to something (like a Q function)
- Improve the policy
Specific algorithms
- Policy gradients: directly differentiate the RL objective
- can be stabilized by a value function baseline (control variate)
- Value-based: estimate value function or Q function, and the policy comes implicitly
- Actor-critic: estimate the value function or Q function, and then optimize the actor based on it. A little bit of a hybid between policy gradients and value-based algorithms
- Model-based RL: estimate a transition model, and then use it for planning or use it to improve a policy, or something else
Why do we have different algorithms?
There are a few tradeoffs
- sample efficiency
- stability and ease of use
- different assumptions (stochasticity, continuity/discrete, or episodic/infintie)
- different settings (simulation, real life, etc)
- is it easier to represent the policy or the model?
Efficiency
The most important question is if the model is on-policy or off-policy. On-policy is very inefficient, but it can have its perks.
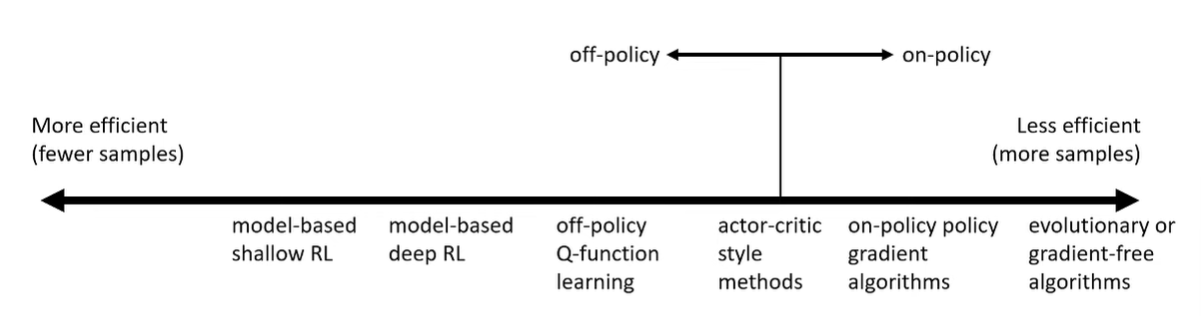
Stability
When you’re fitting a value function through DP, you aren’t guaranteeing anything. However, when policy gradients, you are directly optimizing the objective.
Assumptions
- Full observability is a common observation, which is basically meaning that we see things as MDP and not POMDP (if you’re optimizing based on MDP assumption in a POMDP, the problem becomes not solvable)
- Episodic learning: we can reset after each one
- Continuity or smoothness: there is some continuous value function (not necessarily a continuous reward!)