RL Basic Theory
| Tags | CS 234Reviewed 2024 |
|---|
What is reinforcement learning?
The key objective
The key objective of RL is this:
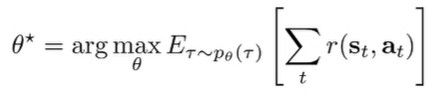
This can be rewritten in terms of the state-action marginals (essentially the distribution of states and actions at any given time , computed through inference).
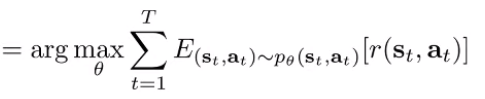
What it involves
RL involves
- optimization of a utility measure
- delayed consequences (to actions)
- planning requires looking into the future (hard)
- learning requires associating cause to effect (temporal credit assignment, also hard)
- balance immediate vs long-term rewards
- exploration (we can only learn what we see)
- decisions impact what we learn about, which means that we can yield very different behaviors
- generalization
Here’s a nice chart that looks at how different AI methods use these things
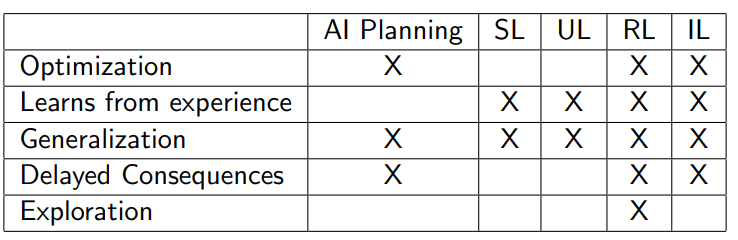
UL is unsupervised, SL is supervised, and IL is imitation learning.
Key vocab
- State: some attribute of the environment that evolves through time.
- Observation: some representation of the state that is accessible by the policy. In the most simple case, the observation is the state
- Action: something you take on the environment
- Reward: a utility measure yielded by the environment
- Depending on the literature, you might get . In this class, we care mostly about . So, you can think about the reward as being calculated immediately after you “submit” the action, and then the transition model yields
- Transition model: the thing that moves from to . This can be deterministic or stochastic
- Policy: the thing that maps from to , to interact with the environment. Can be deterministic or stochastic.
Big questions
What questions do we ask?
- How much does the fitted Q function differ from the optimal Q function? Can we show that it has a difference less than with probability at least ?
- How much does the true Q function for a policy differ from the Q function of the optimal policy? (this is different than the first question, because fitted Q function can make mistakes).
- If I use a particular exploration algorithm, how high is my regret?

What assumptions do we make?
For exploration problems, we typically show worst case performance.
For learning problem, we abstract away exploration by essentially sampling any sample you want from the MDP. In other words, you assume access to for all .
It’s generally not possible to show that an algorithm converges all the time. However, we can start to understand how problem parameters can impact the output. We can use precise theory to get conclusions that we can approximately apply to the real world.
Theory often allows you to get heuristics!
Environment
There are a few attributes of the environment to keep in mind
- Is the state Markov? I.e. does it satisfy Markov property?
- Deterministic or stochastic dynamics? (deterministic means that you can easily plan through the environment)
- Is there a lingering state? i.e. do current actions influence only immediate reward?
banditsdon’t have a lingering state. Instead, actions only influence the reward you get in the current timestep. You can remember this by thinking about a row of slot machines.
Agent
The RL algorithm typically contains one or more of a model, policy, and value function
A model-based agent uses an explicit model. It may have a policy and/or value function…it depends.
A model-free agent has no model, but it has an explicit value function and/or policy function.
Model
A model is contained by some agents, and it’s the proposed behavior of the world. You can have a transition model which predicts . You can also have a reward model that predicts .
You learn the model; it’s not correct to begin with. But once you have the model, you have more freedom for planning.
Policy
A policy maps from states to actions. It can be deterministic or stochastic.
A deterministic policy can be good if the environment is easily exploitable. But a stochastic policy is good for learning, and sometimes it’s important even for rollouts, especially in an adversarial situation with gameplay.
Value function
A value function is the expected discounted sum of rewards
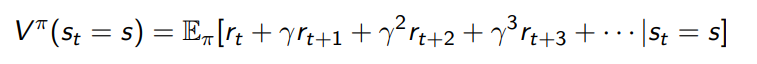
With a value function, you can quantify goodness and badness of states and actions, which helps you make decisions.
There is a discount factor which allows you to adjust how much you care about the future.
Control vs evaluation
The agent can do two things: it can either control or it can evaluate.
control is applying the policy in the world to maximize rewards. evaluate is predict the expected rewards following a given policy. Sometimes, you can accomplish both at the same time. Other times, you may only be able to accomplish control. It depends on which approach you use.