Multi-Task Learning
| Tags | CS 224RExtra |
|---|
Multi-Task Imitation Learning
The idea is actually pretty simple: just supply some sort of latent vector with the policy to specify the task we need. The latent can come as a one-hot, a goal embedding, or text instruction, or something else.
It is common these days to use text cmbeddings as a task representation (RT1)
Relabeling data
As we will discuss below, we can improve performance by segmenting trajectories and making every intermediate state also a goal in some training run.
Multi-Task Reinforcement Learning
For multi-task RL, you just include the task as part of the state, and now you have one singular MDP that you can run standard algorithms over.
Multi-task RL benefits from cross-task generalization, easier exploration (ask different policies to do exploration) and allows you to request behaviors sequentially, yielding longer-horizon tasks. It can also help with reset-free learning (get a forward and backward policy in tandem).
Gradient Surgery
In reality, when we try to do multi-task RL, performance drops significantly. Why? Well, if you plot the cosine similarity of the gradients between tasks, you will see that there is a very non-trivial number of gradients that act in opposition to each other.
We can try to mitigate this problem by literally projecting gradients to prevent any opposing component
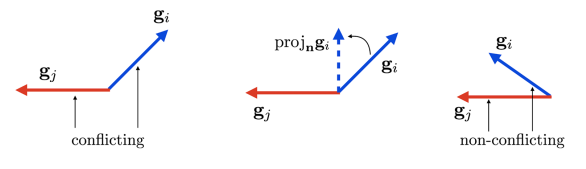
And this yields a really large improvement in overall multi-task performance.
Relabeling Data
We can always relabel a trajectory from one task with the rewards of another, making it accessible for that task as well.
Algorithm

This is known as hindsight experience replay, and there are many ways of doing it. Primarily we search for an optimal way of picking tasks to relabel to. We could select randomly, or select the tasks where the trajectory still gets high enough reward, or we can use some other potentially more sophisticated mechanism. This is still an active area of research.
As it turns out, even rewards of zero are useful for Q learning, as it tells us what not to do. (this is not the case for policy gradients, as trajectories with zero reward are essentially eliminated from the loss).
Goal-Conditioned RL
We can just add a goal representation into the model. We can also use hindsight relabeling to augment performance.