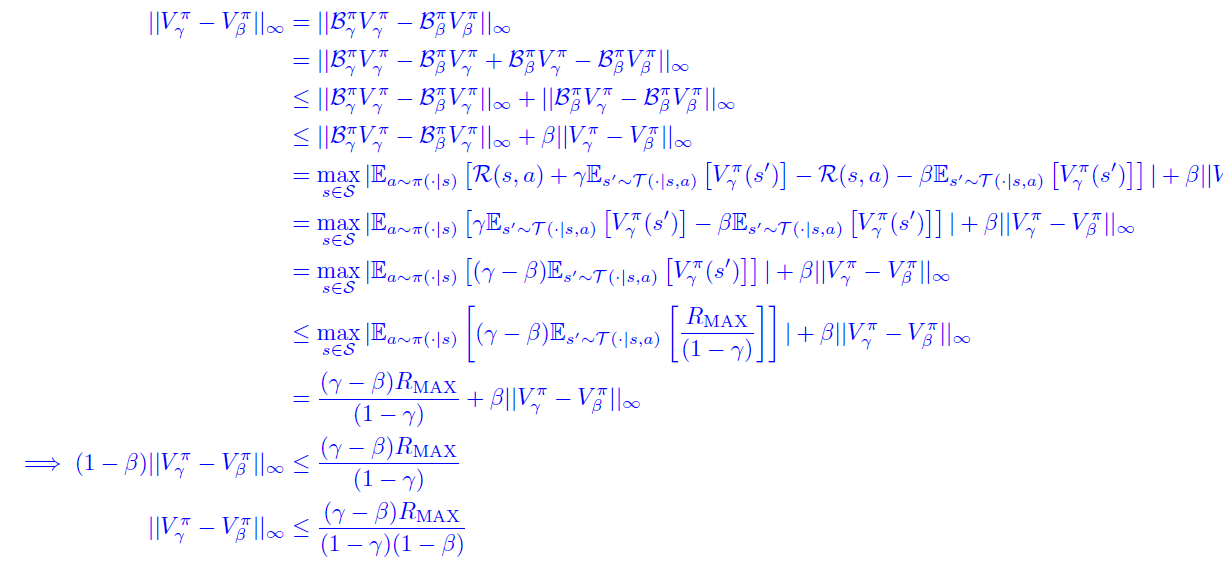Model-Based Tabular Control
| Tags | CS 234TabularValue |
|---|
Ways of understanding V and Q
- (this should be true for a converged value function in the tabular world
- (this is what the value function is approximating, the average return based on an expectation across trajectories).
- (this is true for a converged Q function in a tabular world)
-
Q is used for control, V is used for evaluation. They have an intimate connection with each other.
Policy Iteration in an MDP 💻
policy iteration is the gradual creation of a policy in a systematic way that yields a good policy. We do this with a two-step process:
- make a good policy evaluation of
- make a policy improvement based on this policy evaluation and yield .
V function (step 1)
Through the bellman backup, you can yield a perfectly accurate . This is done for an infinite horizon value of a policy, by default.
But how do you use it?
Q function (step 2)
How do we make a good policy based on policy evaluation? Well, we previously wanted to take argmax over , but that was too impractical. To help, we need to define a new function in terms of the V function we got in step (1). We call this the Q function:
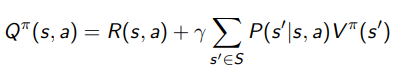
You might recognize this as the inside of the expectation bracket of the bellman backup. In other words,
so as much as we are building from , we can just as readily build from . They are inherently interconnected.
Intuitively, the Q function means “take action a, and then follow forever”
Now, we propose to let the new policy follow this rule:
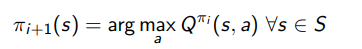
and this is the policy improvement. Now, we will show some critical things about this approach
Monotonic Improvement of policy 🚀
We define a monotonic improvement in a policy by this definition
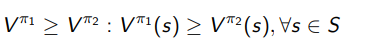
here, again because we are dealing with a tabular environment, we assume that every is converged.
We will show that the policy improves monotonically if we use the policy iteration algorithm defined previously.
Proof (fundamental property between V and max Q, then recursion)
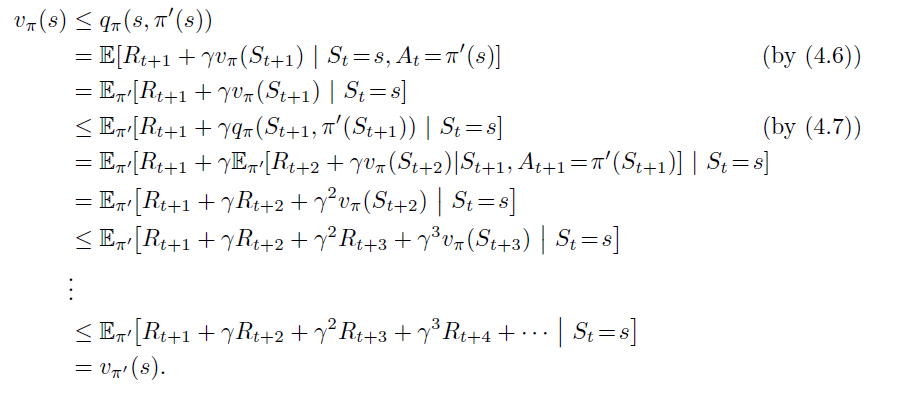
the reason why the first inequality holds is that we can definitely substitute in , and it will be an equality. When we improve over this in policy improvement (see above), we can’t do any worse than that.
We see here a recursive proof, where we make a rollout of the definition of over and over until you get to the base case.
Key results from monotonicity 🚀
If the policy stops changing, then it can’t change again. We can show this inductively. Suppose we had . Then, we know that (or at least their maximums match). Therefore, if we define , we know that
So, if , then , and the rest inductively follows.
There is a maximum number of iterations of policy iteration: because policy improvement is monotonic and because there is only a finite number of policies, you will eventually converge on the best.
Bellman Operator 🐧
We define the bellman operator as a function that runs bellman backup on a value function. When we talk about value iteration (below), the bellman operator is defined as
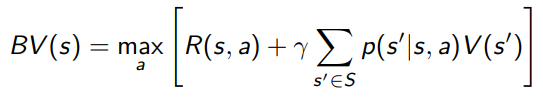
When we talk about policy evaluation in our previous setup, we define the bellman operator as
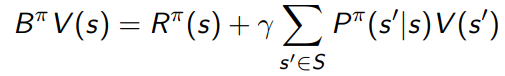
which means that in policy evaluation (above), we can see it as applying the operator repeatedly until things stop changing
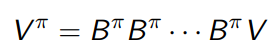
In the next section, we will show some neat things about this operator. Essentially, is a fixed point of the operator.
Contraction 🐧
We define a contraction as some operator and some norm such that .
Intuitively, if the norm was L2, applying this operator to any vector will shrink it towards some common point. We want to show (below) that the bellman operator is a contraction on the infinity norm.
Extra: Asynchronous Bellman
What if you updated the value function one element at a time? Well, you can’t say that this one-element update is a contraction anymore. You can say that it’s not an expansion, i.e. . You also know that for the affected state, it is a contraction.
Putting this together, you can claim that applying of these single-value updates in-place will yield a contraction (i.e. changing the values one by one).
Value iteration in an MDP 💻
You can think of policy iteration as a slow dance between the policy (implicitly defined in terms of ) and the value function . Again, it’s a dance because you make a future policy from a past policy evaluation. You can think of it as bootstrapping.
But in this process, you have a policy that slowly improves. In value iteration, you ditch the policy altogether. It just doesn’t exist. You immediately try to compute , which is the value function of the optimal policy.
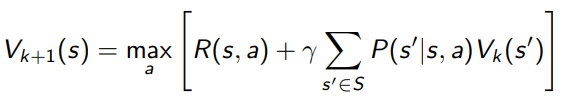
or .
To extract the optimal policy, you just need to do
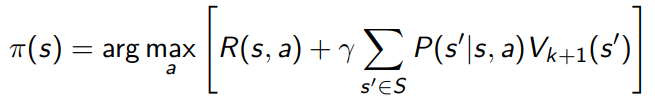
Value iteration vs policy iteration
Now, this is a common footfall: you might think that value iteration is just policy iteration in disguise. After all, you say, isn’t the right hand side just ? Isn’t this just smushing the two steps together?
Here’s the slight but important difference
- Policy iteration will compute infinite horizon value of a policy and then improve the policy through that means. This is because we have a policy, even though it’s implicit, it’s still a policy.
- we showed that policy iteration yield a monotonically increasing policy, which is enough
- this is related to policy gradients, which we will cover later
- Value iteration never has a policy. You can imagine it as starting from an end state where , and then greedily maximizing . This gets us the for the optimal policy acting on the state before the end state. Then, imagine moving backwards to the state before . The value iteration step will make the for the optimal policy acting on the state before , and so on and so forth.
- as another way of understanding it: policy iteration there’s a set solution. In value iteration, you’re kinda chasing your own tail a little bit. We actually need to show that the bellman backup is a contraction.
Here’s another way of understanding the difference: with policy iteration, if you pull a out of the algorithm prematurely, you can say very little about it. In contrast, for value iteration, if you pull a prematurely, you can say that it is the optimal value function for steps, with being the number of times it’s been run so far.
the tl;dr is that policy iteration is a story of bootstrapping, while value iteration is a story of planning. If you run it long enough, the will be optimal at any state. Namely, if the environment is ergodic and you need steps to reach anywhere, then you only need to run value iteration times.
Will value iteration converge? 🚀
Well, we seek to show that this is true (infinity norm)
Proof (using properties of maximums and infinity norms)
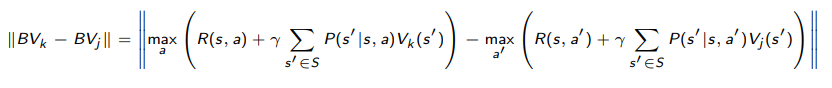
We use the critical insight that . Intuitively, this is true because is the closest to that gets. So we can always do better by sweeping a line.
This yields the inequality
And we know that by the definition of the infinity norm, so we can actually strengthen the inequlaity
and the probability collapses to 1, so we get
and we drop the maximum because there are no more left. So, we get on the right hand side, so we conclude that as desired.
Is the convergence unique? 🚀
Here, we show the uniqueness of the fixed point
Proof (simple fixed point properties and contraction)
We have that from what we said above. Now, say that were fixed points. Then, . Therefore, we have
and if , the only way for this to be true is if , which means that for all , and the fixed points are equal. Therefore, we conclude that the fixed point of is unique.
Is value iteration steps bounded? 🚀
We saw with policy iteration that we can only iterate for at most steps before we get convergence. That was because we trained the value function to convergence every time. In contrast, with value iteration, we sort of slowly approximate . So does the same limit still apply?
It turns out that no, there is no such limit anymore. Intuitively, the value function might “drag” behind and take a long time to converge, even if the greedy policy extracted from it is correct.
Example
Take for example a very simple MDP with one state and one action. So policy iteration would converge in one step.
However, for value iteration, suppose that you start with , and your reward is with . In this case, after one value iteration step, you get . In reality, it is , and you would need to iterate for an infinite number of times to get this exact value.
Additional questions to consider
- Is value iteration going to yield a unique solution?
- Does initialization matter?
Value iteration as finite horizon planner ⭐
Here, we re-explore the thing we just talked about: value iteration can be seen as a way of expanding our planning horizon by one step every time we run the algorithm.
Let be the optimal value if making more decisions. Then, let’s initialzie for all states. Now, we run value iteration
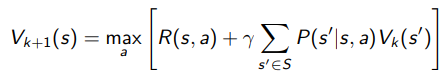
Now, you see how we can integrate one more time step into because we consider this last on top of the current reward. So there’s this branching out of states. It’s kinda cool!
The saga of (and the greedy policy)
To be clear, can be any vector of size . Now, there exists some which is the best possible value function for an environment. Similarly, there exists some for every policy that accuragely describes the return of the policy.
For and , they are fixed points of the bellman backup and therefore must follow , and respectively.
For , no such rule exists. So you can’t write out any relationship that satisfies. But you can use in a policy! Just do a greedy selection
Now, we note that for the greedy policy, we have because the policy is inherently greedy. But be careful—for any other , you have pushing towards and pushing towards , which is the value of the greedy policy based on , an arbitrary vector.
the tricky part is that generates , which has its own that can be very different from .
Reasoning about optimality
Optimality is defined as some where for all in the environment. If you apply to another environment, does the same condition hold for the real vaue function? If so, the optimality still holds. Otherwise, it doesn’t. Linear shifts and positive scales in value functions do not change optimality.
Optimality with shifts in rewards and horizon
- On an infinite horizon, adding a constant to all rewards does not change optimality. You can prove this by writing out what is for every , and you see that they are all shfited by a constant number (an infinite sum)
- On an infinite or finite horizon, multiplying a constant to all rewards does not change optimality as long as is positive. This is because you can factor out a from any expression of . However, do note that if , then we negate the value, and if , then all policies are optimal
- On a potentially finite horizon (presence of terminal states) adding a constant to all rewards may change behavior. This is because certain states may “die” first, yielding a shorter summation of discounted (i.e. where is finite. As such, we may add a value to each that depends on . Intuitively, this is true because if you add more meaning to life, then we might try living longer before doing anything risky that could end it.
- simple example: one state with negative reward, and terminal state. With negative reward, optimal policy terminates immediately. Add something that makes the reward positive, and the agent will choose to stay.
Impact of discount factor on value 🚀
Claim: for any , we have
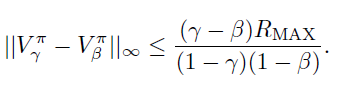
which effectively means that we can bound the differences in the true value.
Proof (adding and subtracting, recursive bellman)