Deep Exploration
| Tags | CS 285ExplorationReviewed 2024 |
|---|
Additional reading


The problem
State spaces can be very large, and you may never get to a good enough reward state to learn from it. What’s more, often local rewards are only weakly correlated to the final objective. How do we explore? This is actually a fundamental question of exploration vs exploitation. Do we keep learning in hopes of getting higher reward, or do we use what we have?
Count-based Exploration in MDPs
The basic idea
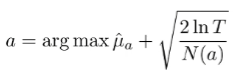
Previously, we had this formula for exploration in the bandit setting. Now, in the the MDP setting, we can use a similar idea. Let be the number of times you’ve seen this state and done this action. Then, you can use an augmented reward
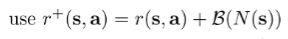
Hash counting
We can also just go back to normal counting, but we hash the state. You can use an autoencoder and it produces hash collisions when the states are similar.
Pseudocounts
Unifying Count-based Exploration paper We can fit a density model which tells us the likelihood of this state. Because it’s a model, it can interpolate.
Now, we want to extract some notion of counts from a density model. As we see more states and fit , the model changes. Can we extract a count that way?
To explore this option, we observe that for true count models, the following is true:
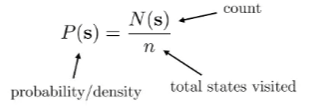
and after we see , we get
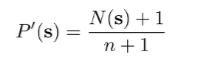
Which means that if we have both and , we have two equations and two variables. And therefore, we can solve for and .
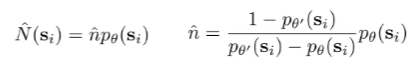
General Algorithm

And then you can use this pseudocount in the UCB algorithm. There are some variants, but the big idea is that it decreases with . Here are some examples
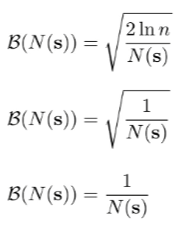
and practically speaking, for , we need to generate a density score, and it doesn’t need to be normalized. Furthermore, we don’t need to sample from them. Therefore, we can consider using an energy model or something simpler.
Implicit density modeling
EX2: Exploration with Exemplar ModelsInstead of of explicitly representing the density function, we can also represent it implicitly through a classifier. The general idea is that we want a classifier to distinguish if something has been visited or not. The state is novel if it’s easy to distinguish from previously seen states, and it’s not novel if it’s hard to distinguish.
If we move briefly to theoretical analysis, if we have a classifier that classifies a state against all past states, we can use the formula for the optimal classifier and solve for
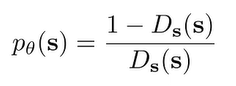
Now, this seems degenerate for a second, but remember that is also present in , or at least a very similar version of . So, would not be . The larger the count of in , the lower will be.
In real life, instead of training one classifier on each state, we can train one classifier that takes in two states and outputs the prediction.
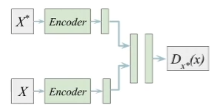
Error-based counting
Exploration by random network distillation. A novel example can yield higher errors when we try to fit the model to this state. Therefore, we can use the error as a novelty bonus!
Algorithm
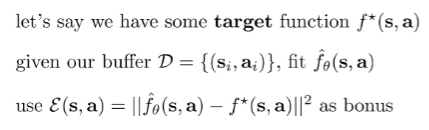
What do we use for this function? Well, we can use as the dynamics of the model . We can also use , where is a random vector. As long as we have something that varies non-trivially with the states and actions, we can get a notion of error. (The random vector case is good because you don’t have to refit a model every time.)
Thompson sampling in MDPs
Deep exploration via Bootstrapped DQN. Thompson sampling in Bandits is sampling parameters and then using greedy selection on these parameter samples. The analog in MDPs is to sample Q functions and act according to that Q function for an episode. We can accomplish this by using a Q function ensemble and select heads at random.
Why does this work?
So Epsilon-greedy is random WRT actions, which basically result in random vibrations. But if we sample Q functions, we essentially sample different life philosophies. It’s an abstraction on randomness
in general, it doesn’t work as well as count-based, but it also doesn’t require any hyperparameter tuning and it’s pretty intuitive. We train this model from bootstrapped data.
Information gain in deep RL
We want to select in an action that gives us the most information about some hidden variable, . But what information do we care about? Reward? But that’s sparse.
But what about state density? If we want to gain information about state density, you’ll do novel things.
What about dynamics? Gaining information about the dynamics means that we are leaning things about the MDP.
State density and dynamics are good, although they are mostly intractable. We need to make some sort of approximations.
Approximating the information gain
We can try prediction gain, which is just
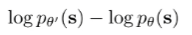
We can also use a stronger method by modeling a hidden variable and optimizing for
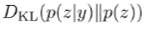
This objective is explored in VIME
VIME
In our case, , and our observation is a transition . So, our objective is
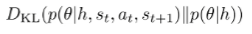
where is the history of prior transitions. Of course, this objective is not tractable because you need to estimate . We use variational inference to estimate an approximate posterior and this allows you to optimize the variational lower bound to
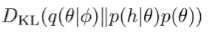
This is the same objective as above because , but because doesn’t involve , we can remove it.
We can express as a product of independent gaussians (so a Bayesian neural network), and the represents the means and variances of the gaussians.
During test-time, we can fit the model to get but also , which is the model after we get the new transition. Then, we compute
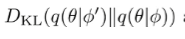
So essentially, you try updating the network and we add a bonus to the amount that the parameters change, which is the same as information gain.
Other ways of using information gain
- use model error or model gradient, etc