Approximation and Fitting
| Tags | Applications |
|---|
Tips and tricks
- Probability distribuiton: add a constraint
Notes on norms
Least squares objective is minimizing the sum of squares, not the L2 norm which has a square root. The L2 norm, or any sort of p-norm is “linear” in each component because you raise the component to , sum, and then take the power.
Norm Approximation
The big objective is to minimize , where and . This norm could be any valid norm.
Ways of interpreting
- Approximation: Get to be the best approximation of
- Geometric: is the point closest to in the norm
- Estimation: get a linear model that matches the observed data as close as possible
- Optimal design: is the resutl, is the best design for some constraint
Variants
- Euclidian approximation: closed form solution
- Squared euclidian approximation: also closed-form solution because you can write the squared norm as .
- Chebyshev / minimax approximation: solved through LP
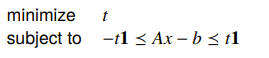
- L1 norm: solved through LP
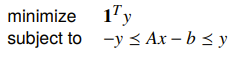
Penalty Approximation
This big objective is to minimize subject to . Here, is a scalar, convex penalty function.
Common examples
- Quadratic
- Deadzone linear
- Log-barrier
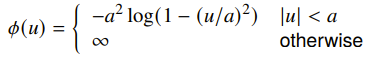
- Huber (linear growth for large makes it robust to outliners)
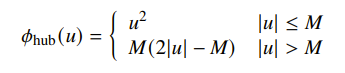
These different penalty functions can yield quite different losses. Most notably, an absolute value cost typically yields a sparse solution.
Least-Norm problems
This is when you minimize such that . There are a few interpretations
- Smallest point in the solution set of
- Estimation: if are perfect measurements of and the norm is the implausibility, then is the most plausible given the constraints
- Design: if the norm is something related to efficiency, then is the most efficient
Variants
- least euclidian norm
- Least sum of absolute values: solve this through LP
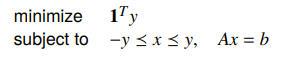
Regularized Approximation
Regularized approximation is a bi-objective problem where you want to reduce the quantities of two things
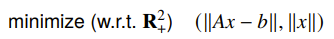
Common interpretations
- estimation: you want to fit something under the prior that it is small
- optimal design: is expensive, so you want to have a cheap solution
- robust approximation: smaller is less sensitive to errors, so you want to minimize this
Variants
You typically scalarize the problem to get , and this traces the optimal tradeoff curve (see notes on Pareto optimality)
- If we have L2 norm, we call this
Tikhonov regularizationorridge regression, and it has a least-squares solution
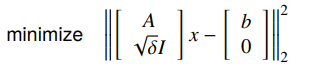
You can also have a linear dynamical system defined as
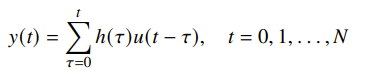
This particular setup is useful if you want to shape the impulse response of a function. More precisely, you want to optimize over three properties: you want to reduce the estimation error, minimize input magnitude (the norm of ) and you want to reduce variation of the input (the difference between and should be small). Once you scalarize, this problem is a regularized least-squares problem becuase all of the things can be expressed as sums of squares.
You can also just try to fit a signal directly, using different variatns of the regularizer that cares about how the changes through time.
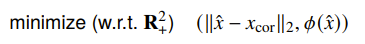
- Quadratic regularizer can remove noise, but it acts like a lowpass filter so it can’t do sharp edges
- Absolute value (L1) regularizer can keep the sharp curves
- Huber regularizer is robust to outliers
Robust Approximation
The big objective here is to minimize but the is uncertain. Under these conditions, there are two philosphies:
- stochastic: assume is random, minimize the expectation
- worst-case: minimize
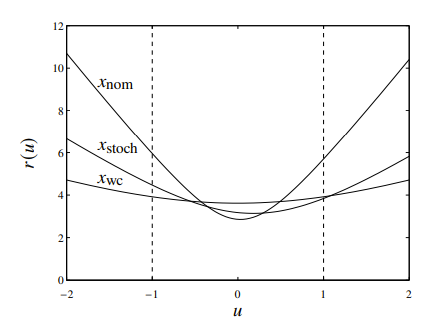
Examples
If where , then you can compute both the stochastic and the worst-case. In general, they both perform pretty well. The plot shows .
The stochastic robust least-squares setup is where we have , where for some matrix. We want to solve the stochastic least-squares problem, and it turns out that if you do your algebra out, you get
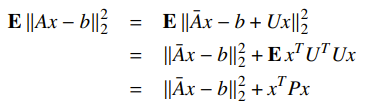
Which is essentially a strategically regularized least squares problem. If your is a scaled identity matrix, then this is just ridge regression.