PCA
| Tags | CS 229Unsupervised |
|---|
From factor analysis
Factor analysis learned a matrix that effectively turned a low dimensional representation into high-dimensional space. It used the EM algorithm to get the encoding. As it turns out, if we only care about low-dimensional representation, we can also use principal component analysis (PCA), which only uses eigenvectors
Often, your different dimensions can be highly correlated. For example, you might have miles per hour and kilometers per hour. In reality, you only get one piece of information. We can extract this through PCA!
PCA can work as noise reduction, overfitting reduction, and can even help us visualize high-dimensional data.
Dimensionality reduction
Here's the big idea. How can we project a set of points with dimension onto a subspace of dimension while maintaining as much information as possible? In other words, if were the projection matrix and , then we want to be as close to as possible.
The derivation
Projections
When we talk about projection matrix, we just want to project some space onto an orthonormal basis , the vectors of which make up . We need to find these vectors!
We establish some which we subtract from before projecting. This is just so our later derivation works out perfectly; it does not influence the conceptual understanding of the problem. To project, we just do
Now, would be in the changed basis, and would both be WRT the canonical basis. Here's the tricky part: we can imagine that we have orthonormal vectors such that we are just projecting onto a rotated coordinate without losing any information. However, when we do compression, we only pick of these (and we order to be the most important, somehow)
We can express as the following:
Think about this for a second—it's important
Cost function
Our error as as follows:
Let's make sure that we digested that correctly: so the first part inside the squared is another way of representing , and the second part inside the squared is what we had above
We note that the two sums can partially cancel and we get
Now, this squared error is actually a dot product. So, we can write this out by splitting into cross terms and non-cross terms
Now, we recall that is an orthonormal basis. As such, the second term just cancels out, and the first term simplifies
So, tl;dr—to minimize the error, we just need to minimize the coefficients OUTSIDE of our selected basis. This makes a lot of sense!
The covariance matrix
But how do we minimize this? Well, let's expand what we know about
Let's rewrite and move the summations around
We did this because .
And if we assign or the mean of the , then we have the following:
(recall that covariance is just )
So our error just becomes finding the minimum of a quadratic form!
Eigenvectors
Here's the rub: Why don't we just use the eigenvectors of ? We need to select some basis that minimizes our error, and any orthonormal basis is equivalent under one transformation. As such, we can pick what is most convenient.
If is an eigenvector with eigenvalue , then
(take a minute to convince yourself of this)
As such, to minimize the error, we simply need to pick eigenvectors to form , and we pick it by selecting the eigenvectors of with the highest eigenvalues!
Algorithm, reviewed
- start from an matrix
- Subtract center mean from each row to form
- Compute covariance matrix of (take a second to convince yourself that this is indeed the covariance. It helps to consider matrix multiplication as a series of outer products.
- Find the eigenvectors and eigenvalues of , and the principle components are the eigenvectors with the highest eigenvalues. It's worth noting that the eigenvectors are the orthonormal basis, and they are in the canonical space (i.e. non-transformed space). Confused? See below for a practical example.
To compress a point, just compute the inner product with these normalized eigenvalues!
Eigenfaces

In eigenfaces, we had an matrix where the are the number of people and the is a flattened version of the image. For example, if the picture were , then .
By computing PCA on it and selecting only the top eigenvectors, we are able to generate eigenfaces, which are the eigenvectors corresponding to the k-top eigenvalues. Each eigenvector corresponds to a picture. We can reconstruct faces by projecting an image onto the eigenface basis. The larger the , the better the reconstruction.
And here's an image of a city reconstructed from eigenvectors

SVD to speed things up
Essentially you write , where is the data matrix (row per datapoint), is a weight matrix, is the singular value, diagonal matrix, and is the singular vector matrix.
You can think of as the coordinate of in eigenspace, and contains he eigenvalues .
SVD helps because you don't need to compute explicitly. Rather, you do some cool math (I'll figure this out later) and eventually get the eigenvectors that you desire.
Another key distinction is that SVD isn’t lossy. You’re just factorizing the matrix into three components. You drop components by zeroing out elements of .
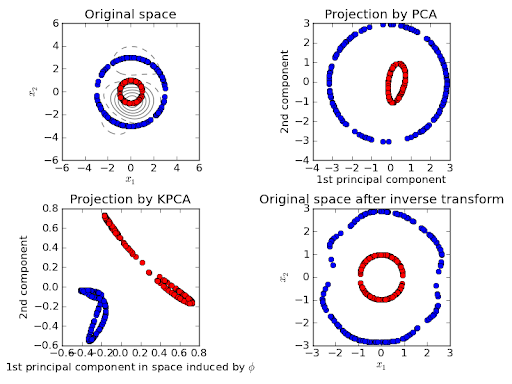
Kernel methods
You can also substitute the dot products we used with a kernel. Without getting into this too much (it's a similar idea), you can express far more complicated features with a kernel.