Logistic Regression
| Tags | CS 229Regressions |
|---|
Logistic regresson
The concept is very simple. Define a predictor that outputs a value between 0 and 1. We define it as the following:
The is a sigmoid function, and (very helpful identity)
Derivation
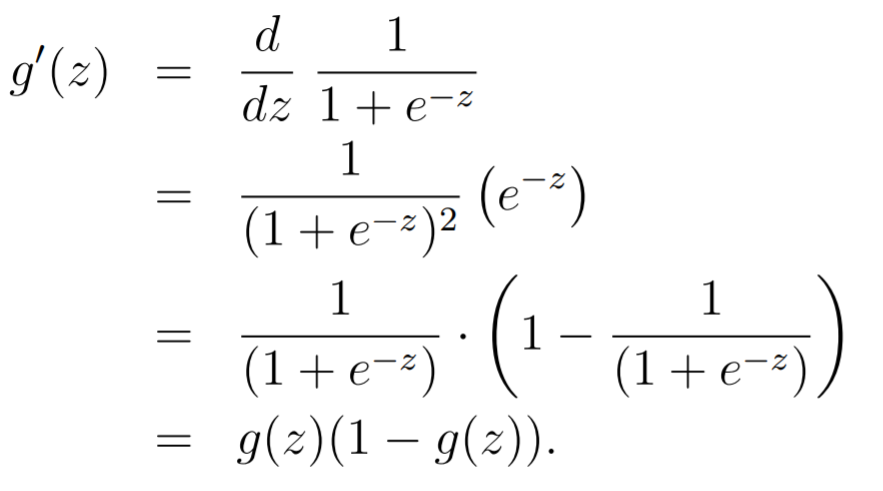
A probabilistic view: deriving the loss function
If we look at things probabilistically, we can sort of view as the output of . It ranges from 0 to 1, and it sort of represents the "confidence" of the model. As such, we can define the following
We can also express this as
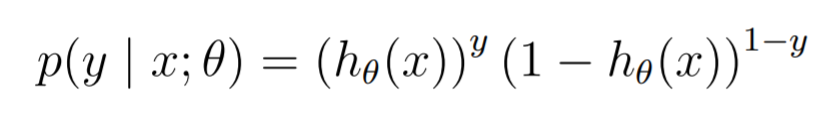
Now, the likelihood is just
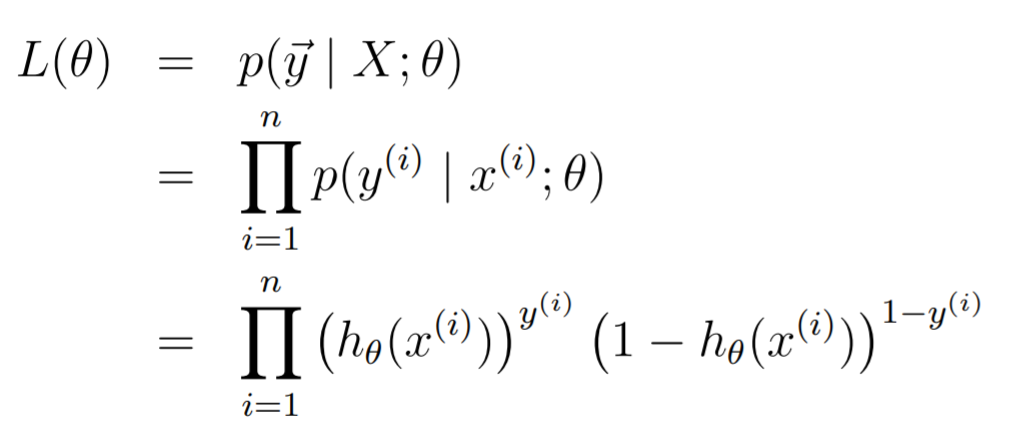
And when we do the log likelihood, we get
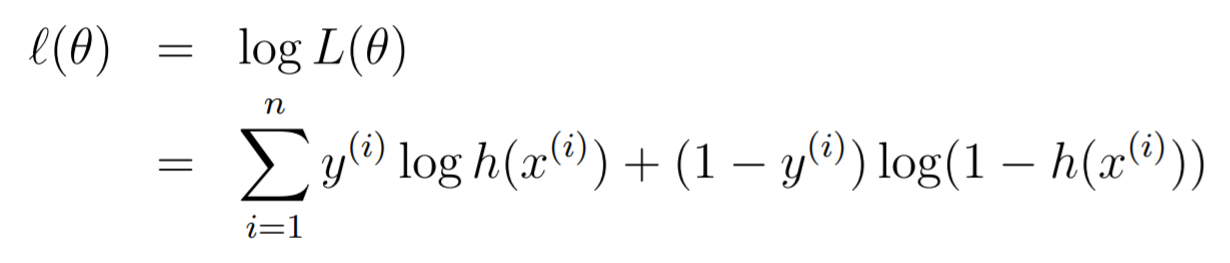
This is our objective—to maximize .
Deriving the update
You can take the gradient through this function and you will get the following (using the derivative identity)
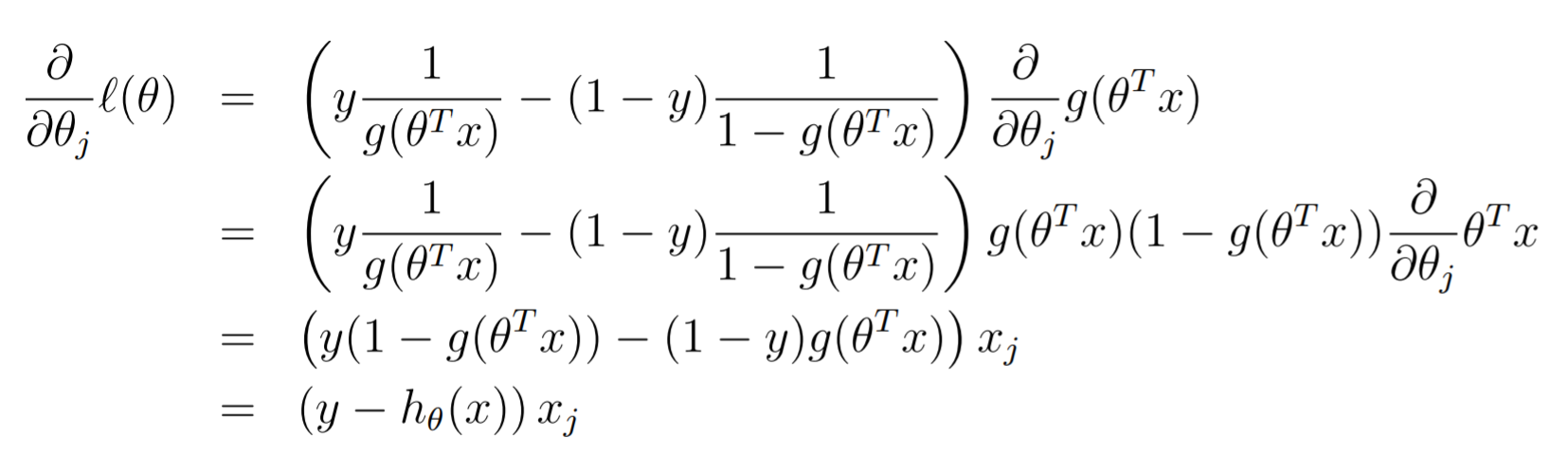
As such, the update is just
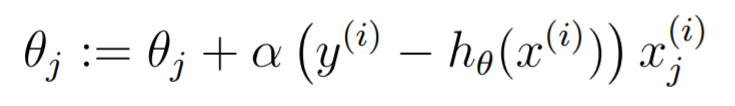
If you wanted to find the hessian, it's just
which you can show is positive semidefinite, meaning that it is convex at every point.
Brief interlude on softmax regression
This is just assuming that the is a multinomial. You can see the math in the GLM section, but you get that
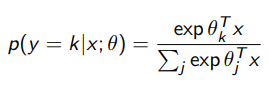
Perceptron learning algorithm
Instead of a sigmoid, if we had a threshold function
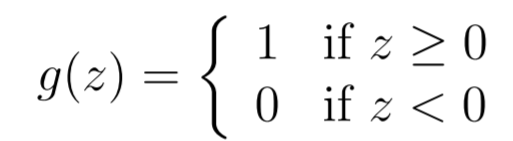
and used the same update rule, we get the perceptron learning algorithm .
The update rule actually has a pretty strong interpretation here. First, let's view the boundary graphically.
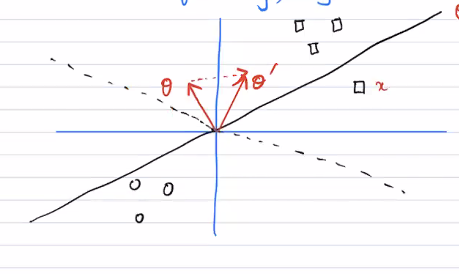
The is orthogonal to the dividing line, because here . Now, say that you got something wrong; you had but (shown in the figure). We know that , which means that we move more towards the rogue point. However, in doing so, they move the dividing line (dotted line) to include that rogue point.
Partially observed positives
This is a pretty neat problem: what if we had partial observability in a classification problem? Say that we had this setup, where is the true value and is the observation
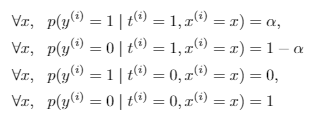
We can show that
In other words, if we observe a positive, then it must be positive.
We can also show that
In other words, the probability of a true positive is proportional to the probability of an observed positive. Taken together, this means that if we wanted to do logistic regression (i.e. model , the true decision boundary is just shifted a little bit.
To derive , you make the key assumption that . In other words, there is no doubt about the true values. However, you can't assume the same thing for , because it could be a true positive and yet not get measured as one. The probability a true positive is ,