L2, Likelihood, DKL
| Tags | Fundamentals |
|---|
The relationship between L2, Likelihood, DKL
Sometimes, you want to do max-likelihood, and sometimes you want to do L2, etc. Is there a connection? Actually, yes!
So as you recall, this is a gaussian PDF:
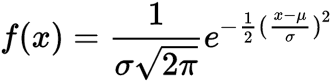
If you take the log-likelihood and set , then you have recreated the L2 objective. You can imagine the as modulating the importance of distance in L2 space. The larger the sigma, the less of a problem it is.
L2 losses also end up being equivalent to minimizing the KL divergence between the policy action distribution and the expert action distribution, as sampled under the expert action distribution (not the other way around).