ICA
| Tags | CS 229Unsupervised |
|---|
The big idea
In PCA, we tried to formulate a basis that captured the most variation in its axes. In ICA, we also try to formulate a basis, but we try to formulate a basis that "decorrelates" the data.
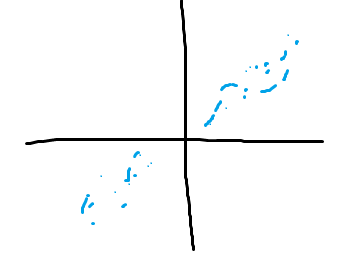

In this example, you see how the left basis creates a correlation in the blue data. But in the right basis, there is no correlation!
We will attempt to motivate ICA again in a more practical case below
The cocktail problem
Suppose that you had multiple people talking at one time, but you wanted to extract the audio from one person. You have multiple microphones so you can get a sense of depth, but how do you parse out this one person?
More formally, you have d-dimensional vector and you have an observation . The vector is a random variable that is correlated among its elements. We want to create a new random variable whose individual elements are uncorrelated.
A mixing matrix will "mix" the elements of and hand it off to , which is also a d-dimensional vector
Can we recover from ? Hypothetically, if were non-singular, this is totally possible. We can find some called the unmixing matrix such that .
So essentially we want to transform as set of random variables into another one
What can't you do?
Well, it's actually more complicated than finding an inverse matrix. The permutation of the original sources are ambiguous, and the scaling is also ambiguous between sources (because you could scale the mixing matrix by and the source by and the output would be the same.
In addition, the sources can't be gaussian. Why? Well, we can show that any arbitrary "rigid motion" (orthogonal matrix) applied to the mixing matrix produces the same outcome. First, we can show that .
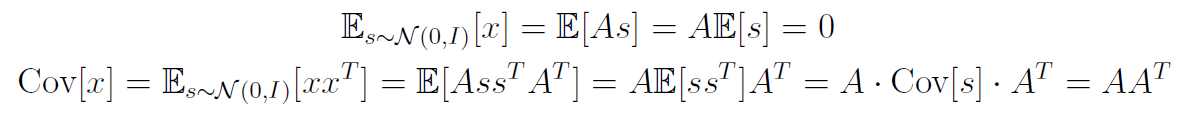
Now, we can apply some rigid transformation such that . Now, we notice that
Therefore, given a random rigid motion matrix , the output distribution of will be unchanged!
Densities and linear transformations
If you have a random variable and you have a transformation , then the density of is not a straightforward as you might think. Imagine if you just put through . You run the risk of creating an invalid distribution that doesn't sum to 1!
To fix this, let . A density transformation is defined as
In a way, the keeps tracks of where things stretch and where things squeeze. We mapped to 's domain by using , but we must account for our stretch debt. This is why the term is there.
For example, le'ts consider the case where shrinks twice to . This means that has double the range, so it should have half the density. Out of the box, the output of the function doesn't change when the input is stretched. This is fine on normal functions, but not on densities that have a clear rule. This is where the comes in, in our previous example—to scale the density by half. Hopefully, this toy example clarifies things.
ICA algorithm
We assume that each source is independent
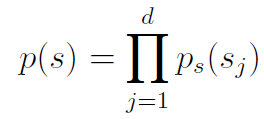
We apply the transformation to the data by using the trick we just discussed
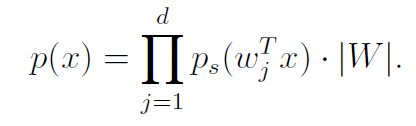
(we just use the row-dot product form of matrix multiplication to convey the different sources
The could take any form, and if you knew what the probabilities are like, then you should substitute that distribution. However, in a pinch, we can use the density whose CDF is the sigmoid function . As such, and we get
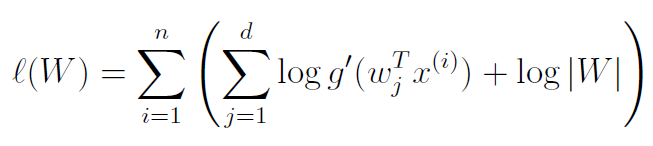
If we take the derivative, we get
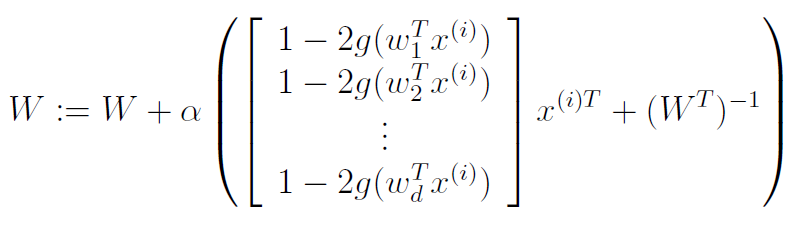
So, after the algorithm converges, all we need to do is compute .