Generative Learning Algorithms: GDA
| Tags | CS 229Generative |
|---|
Where we are now
We've talked about algorithms that can model . These are discriminative algorithms. In other words, "given a set of features, predict if it's in one label class".
However, there exists another class of algorithms that are generative algorithms. These model and and can be used for discrimination indirectly, but they are really doing the task "given a label class, give the expected set of features"
The setup
We need to model , known as the class priors. this is like "what's the probability that this class shows up?" and . Then, we use Bayes rule to get what we want
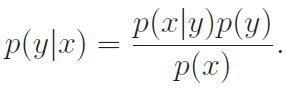
Now, when we are trying to predict which class some belongs to, we only need the numerator because doesn't depend on . This helps with our calculations, as we only need relative numbers. However, in the derivations below, we actually use to be more rigorous.
Gaussian Discriminant Analysis (GDA)
Let (our prior), and let and let .
In other words, we are modeling the features of both classes as gaussians with different means and one shared covariance matrix. The distributions are thus both gaussians of the same shape. Intuitively, it looks like this
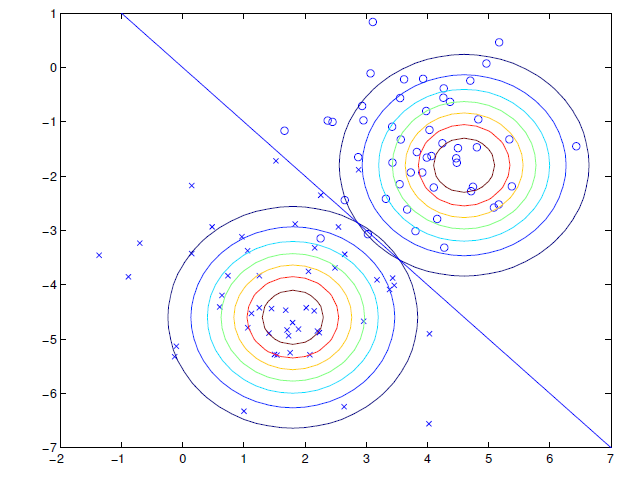
The math
We can write out the distributions like this:
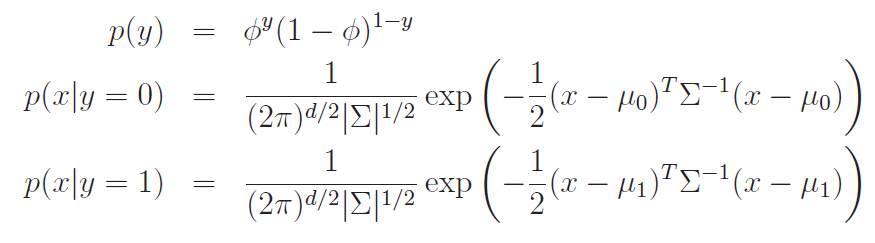
We can define the likelihood function to be just
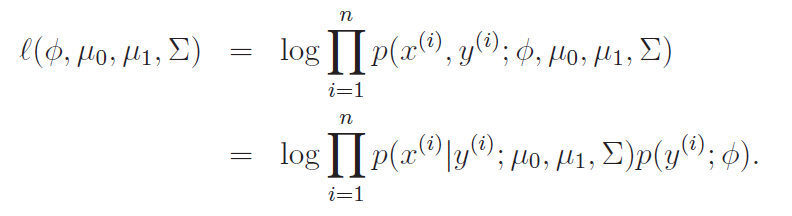
Now, we can derive the MLE as follows
Derivation of
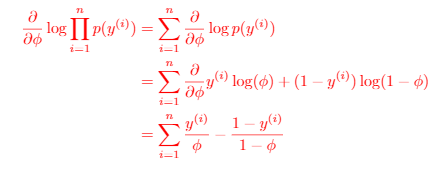
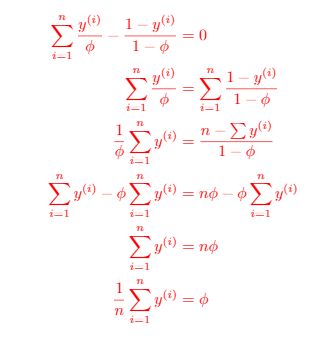
Derivation of : very messy
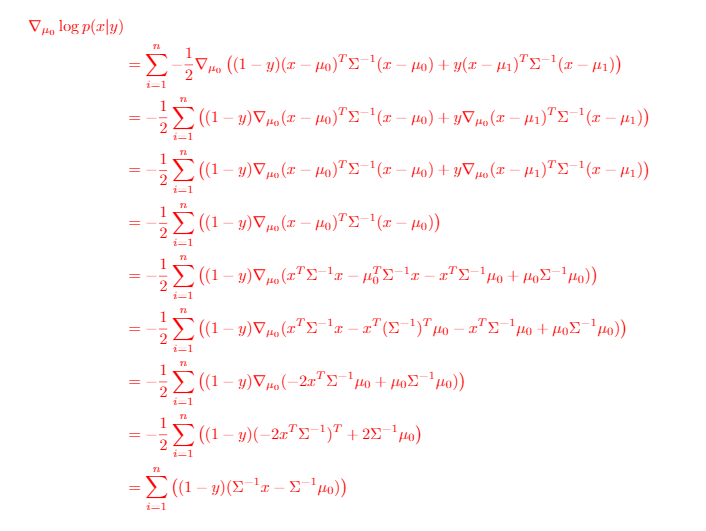
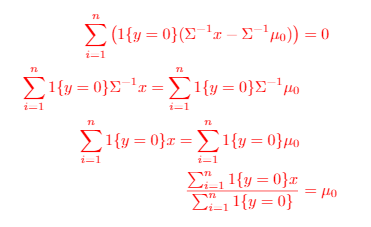
Derivation of : very messy but interesting
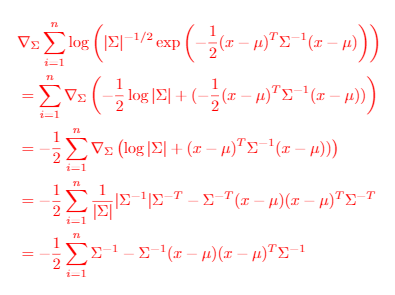
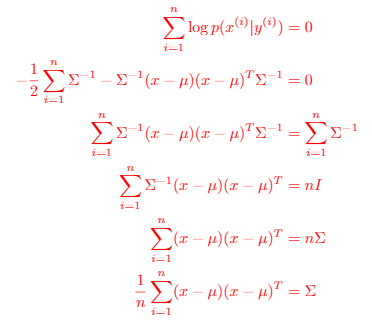
Eventually you will get
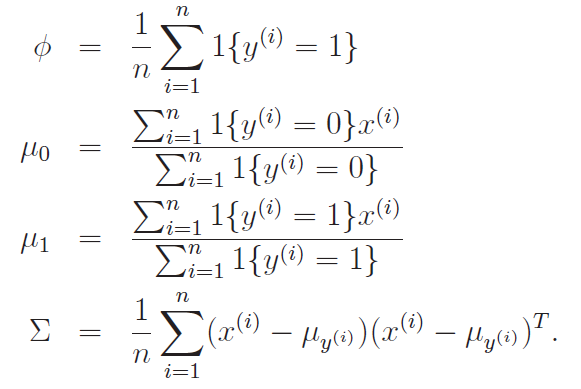
Many of these are intuitive. For example, the prior is just the proportion of , and is just the means of the with respectively. See the derivations above for a more rigorous reason why they are so.
Connection to logistic regression
This is actually really cool. so if you computed the posterior , you will get the logistic regression formula!
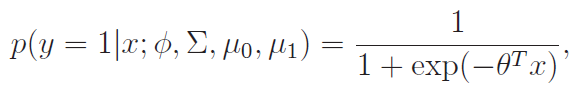
derivation (very messy)
we want to get . In the equation above, the is replaced with

This just means that this generative model is the same as the discriminative model when used in a discrimination context!
Which one do you use?
Well, we have shown that all generative models have logistic posteriors, but it is NOT true that all logistic models have as a gaussian! So the GDA makes stronger assumptions about the data. If is indeed a gaussian then GDA is better. It is asymptotically efficient , which means that there is no better approximation
However, because the logistic makes weaker assumptions, it is more robust. If were from a posison, it can be shown that is also logistic.
If you are sure that the data is non-gaussian, then it is better to not use GDA.
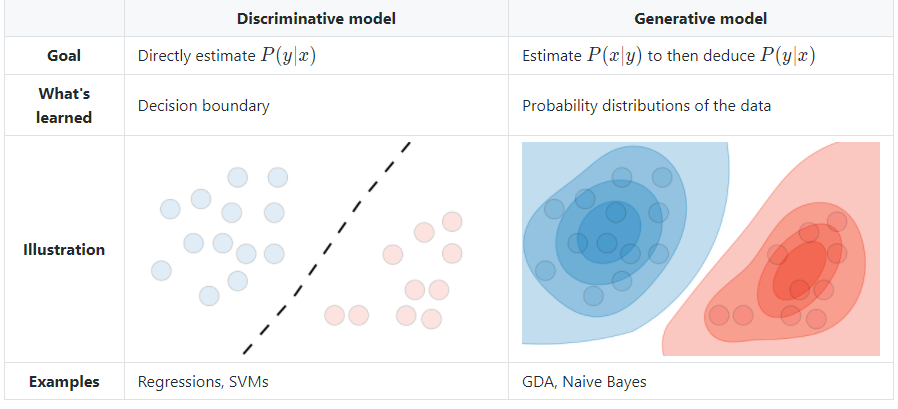
General discussion: discriminative vs generative
Discriminative will try to separate two classes, while generatives will try to model the class distribution and by nature can be converted to a discriminative model through Bayes rule. Generative is therefore more expressive and can do better on smaller datasets as it's always looking for that general model. HOWEVER, generative models require more assumptions. In GDA it was . Because discriminatives are less expressive, it doesn't need this assumption and therefore can be more robust.
tl;dr
- generative performs better on smaller datasets and can even generate data, but requires significant human design choices
- discriminative is more robust
Good summary chart