Generalized Linear Models (GLM)
| Tags | CS 229Regressions |
|---|
A new mindset
A probabilistic interpretation of regression is really interesting, because it unifies many things. For example, in our linear regression, we had , and in our classification one, we had . Can we expand to generalized linear models? And what do these even mean??
Distributions, expectations, hypothesis
A hypothesis returns a single number given . We know that is a distribution. How does this work? Well, you can think about as returning . This makes sense in the case of linear regression and logistic regression, and it's a good thing to think about moving forward.
The distribution is a conditional distribution, whose parameters depend on and . For example, of , this is a function of .
Exponential family
We are about to introduce something a little confusing, but it is needed to work torwards generalized linear models. We define the exponential family as
The is the natural parameter (also known as the canonical parameter), is the sufficient statistic, which usually is . is the log partition function.
The function that gives the distribution's mean as a function of the natural parameter is called the canonical response function. The inverse function is called the canonical link function
When you fix , you get a family of distributions that is parameterized by .
Exponential families include bernoulli, gaussian, multinomial, poisson, gamma, exponential, beta, Dirchlet, etc.
Key properties
- . This is really neat because it prevents us from integrating.
proof: we use a pretty nifty integration trick
Start from something we know: . Therefore, . However, we can expand this out
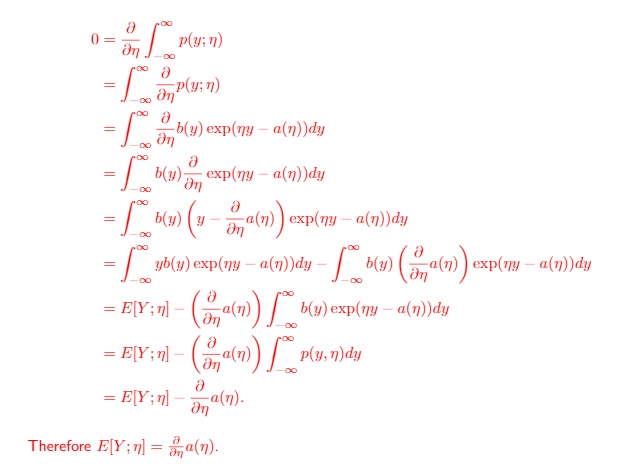
-
Proof: we use what we derived previously
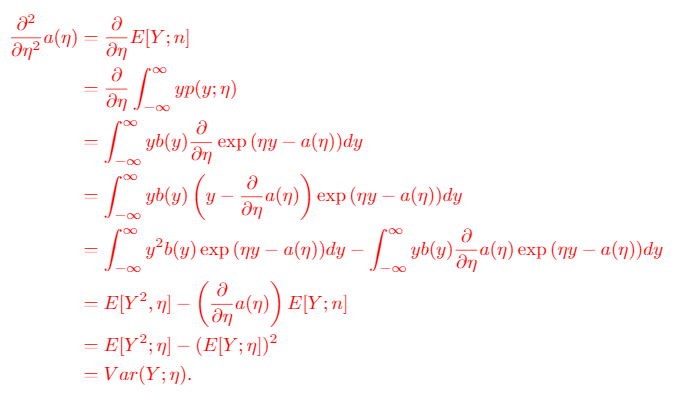
- when we do a MLE WRT , the function is convex
proof:
We will derive the hessian of and show that it's convex

Now, we just need to show that this is PSD:

GLM from the exponential family
To construct a generalized linear model from the exponential family, we make three design choices
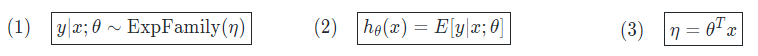
First, that is in the exponential family . Second, that the prediction function is just the expected value of the distribution. Third, that the intermediate parameter is a linear function of (hence the term LINEAR model)
So the exponential family produces a distribution . We use this to model what we want, which is . We can imagine the as being a sort of "latent" variable from which the 1d distribution arises.
To get the final model, we derive a canonical response function that maps to the canonical parameters of the distribution like which give us implicitly.
To derive this response function, we just look at and try to squeeze it into the exponential family form.
To summarize:
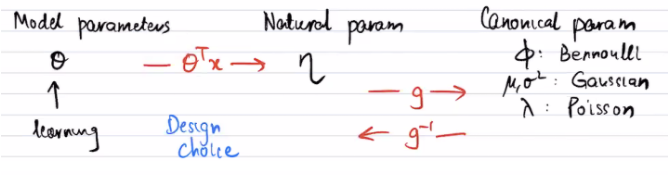
You can actually think of as an expression of GLM. The is just the , and the is the canonical response funciton!
Optimizing your GLM
The only learnable parameter is . Again, think of as your latent variable that helps map to.
For any models in the exponential family, we optimize our model by doing
Or in other words, fit the with the with as high of a probability as possible. To derive the update rule, we start with the distribution, like the gaussian for linear regression or the bernoulli for logistic regression. Then, we substute in for the parameters like or . This substitution turns the original distribution, which depends only on and some parameters, into a distribution conditioned on both and . This allows you to take the derivative and optimize.
Deriving the general update rule
Our distribution is
By our design, we have
Our objective is to perform MLE, so we can just do log-probability:
Taking the gradient gets us
Therefore, the update is
Interestingly, as we observe, we get , which is what we showed before as well.
Derivations of distributions

Strategies
- rewrite things as . This often loosens things up with inner exponents, etc
- group all terms with together. The coefficient becomes your
- Find the canonical response function by solving for the parameter that forms
- Make modifications to the response function to solve for the expectation
- for example, in a Bernoulli distribution, you can get , but you need to scale it by to get (which is )
- Replace
Let's look at some examples!
Bernoulli as Exponential Family
Canonical parameter:
The Bernoulli is in the exponential family. We can expand the equation like this
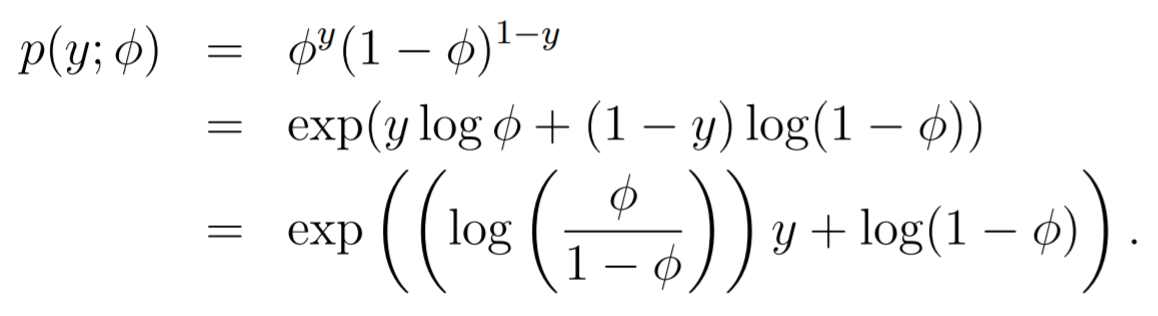
Canonical response function: We see that , which means that .
Connection to the Sigmoid
One thing you might have noticed is that the canonical response function is just the sigmoid! This means that if you assume that things are distributed as bernoulis, the distribution's parameters are best described by a sigmoid! Neat!!
Gaussian as Exponential family
Canonical parameter:
You can do a similar expanding from the gaussian equation (for now, we assume that
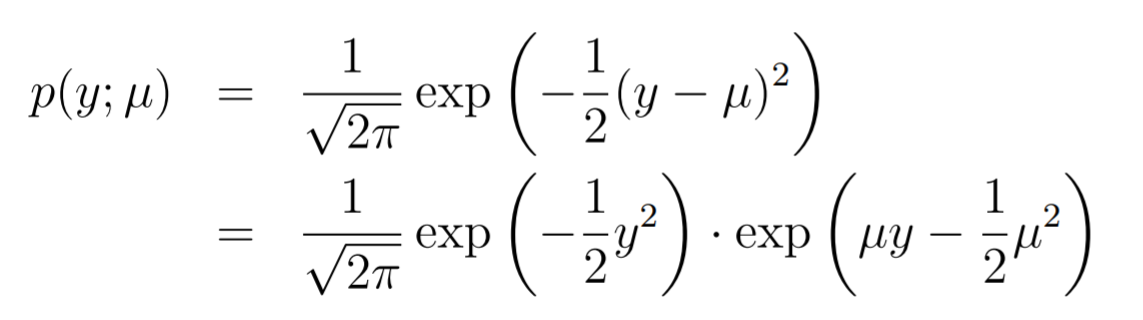
Now, we see that
Here, we see that the canonical response function is just .
Multinomial as an exponential family
Canonical parameters: , where each represents the probability of one outcome. Note how you would need a vector to represent this.
*Because we are dealing with essentially a vector of outcomes, we are dealing with vectors instead of scalars. We have equal to the "category" of the outcomes, and we define as
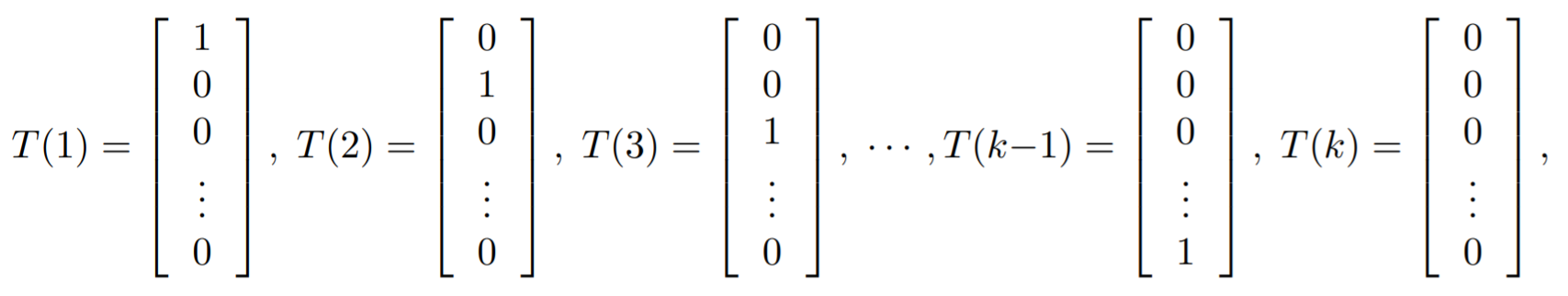
You can also write this as
which will be more important below.
Now, we are ready to derive the exponential family. We start with the multinomial and make our substitutions. It's important to express as a sum of other , as it is a constraint
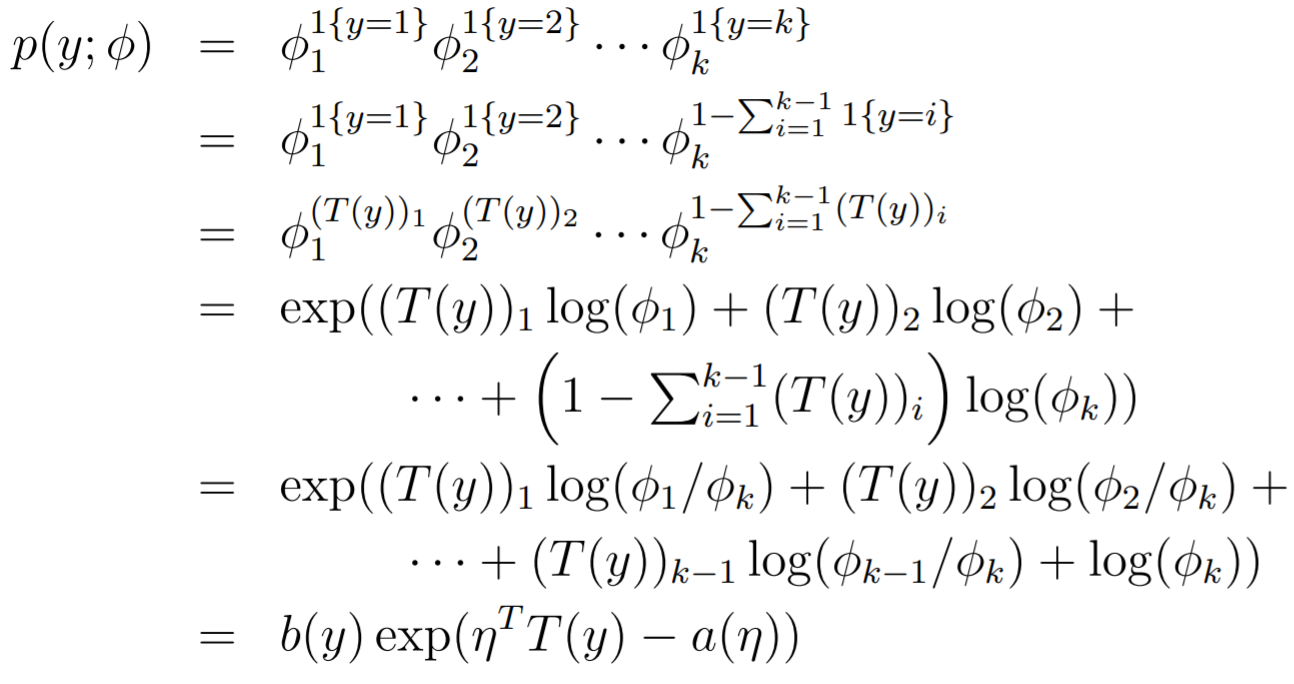
Where
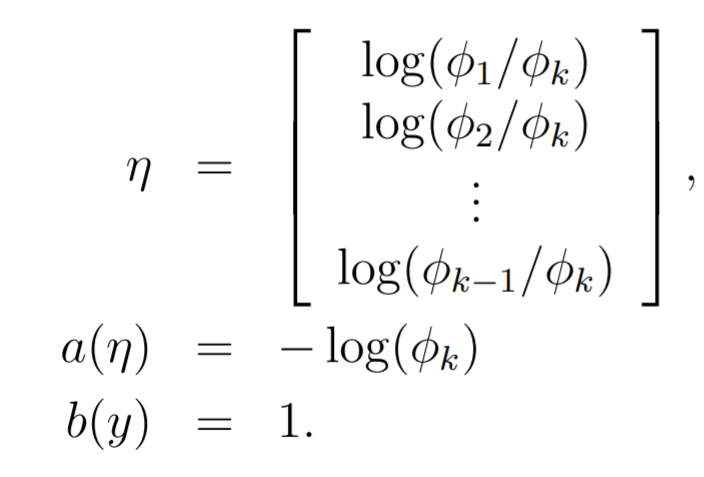
Now, let's look at the canonical response function. If you look at , we see that the function is just
To get , let's use the identity that :
And this means that , which means that
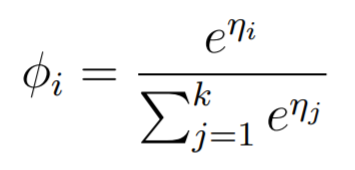
. To recap, what is shown above is the canonical response function for the multinomial distribution, which maps between a vector of logit values to a probability distribution. This is known as the softmax function.
Constructing GLM's
Ordinary Least squares
Recall that . As such, we have
However, we know that the expectation of a normal is just , and we have previously derived that . Therefore, . Neat!! This is what we expected!!
Logistic regression
Here, we actually derive why we use the sigmoid!!
Recall that , where is defined implicitly with . Now, the following is true:
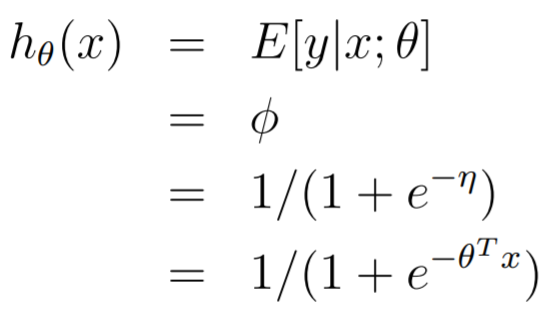
And we arrive upon our logistic regression equation! And this kinda derives the sigmoid function!!
Softmax regression
This one is interesting. Instead of a binary classifier, we have a value classifier, and we assume that it's distributed according to a multinomial distribution whose parameters depend on the input . Now, we have previously derived the canonical response function for the multinomial:
Furthermore, we know that , so we get the following:
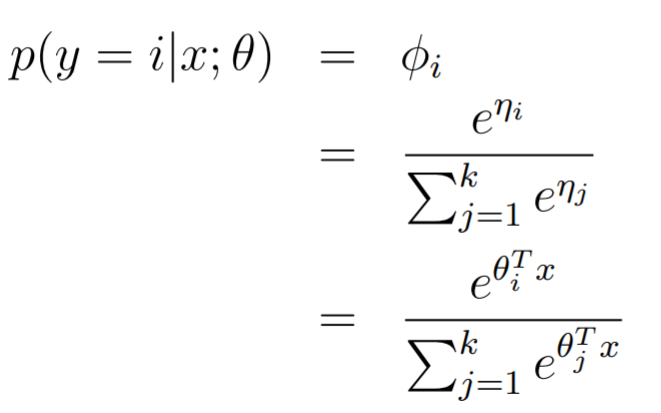
Another way of thinking about this is that we find the logit (the ) and then we apply a softmax.
Softmax regression: The graphical intuition
The matrix for is just a row matrix with one parameter for each class, essentially.
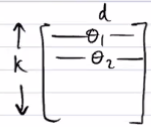
So you can imagine as running separate linear "tests" on the current point, like the graphic shown below:
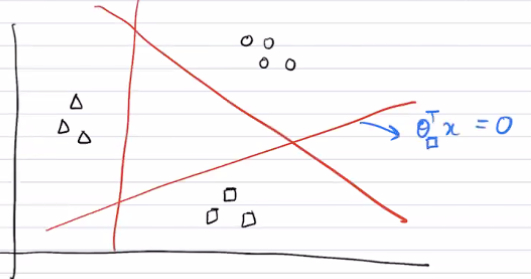
Each of these results are fed into a softmax and we get a probability distribution. The intuition is that the groups are separated by these lines, and depending on how close they are to the boundary, we get different "activations".
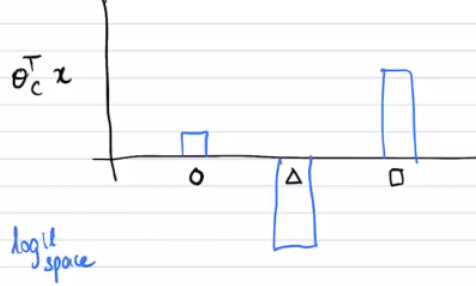
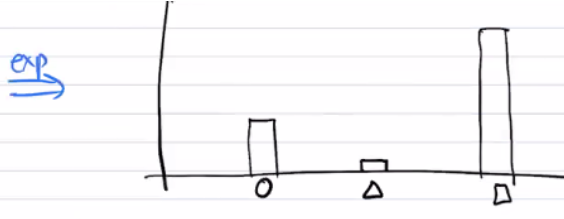
The raw logit results can have a variety of different results, but the one that has the highest score (i.e. the "test" the returns the most positive result of this point being in that class) will have the highest value in the probability distribution.
The tl;dr: softmax regression means running multiple agents and having them vote for which category this unknown point is in.
Softmax regression: Learning
To learn the parameters , we can use a simple log likelihood:
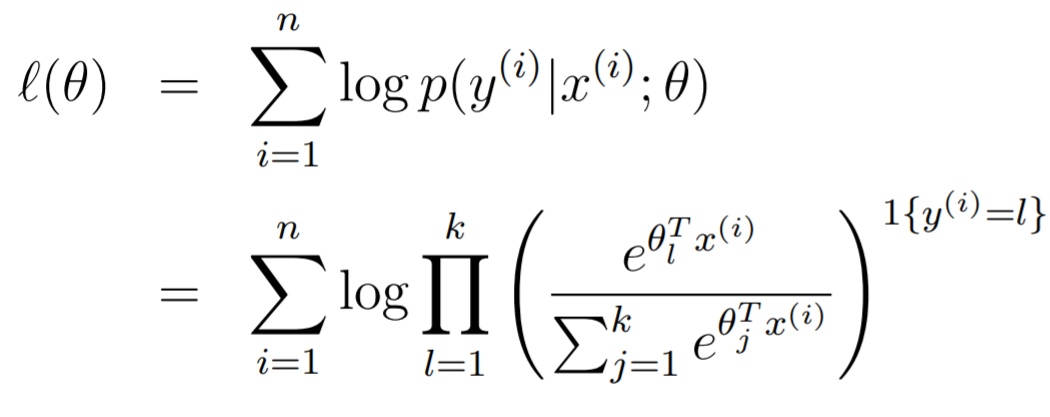
If you wanted to derive the gradient, it is feasible.
We can also learn using a different, loss-based approach called cross entropy. In cross entropy, we compare two distributions and penalize based on their differences. This is done with the following equation
This is like entropy but it's a mutual sort of entropy. Sampling from the truth , how "surprised" are we to see in a location?