Video Understanding
| Tags | CS 231N |
|---|
Videos
A video is just a sequence of images, which can be represented as a 4D tensor of shape . Videos are often very big, so we often reduce the resolution and train on short clips, like 16 seconds with a low FPS.
When running the model continuously, you just run the model on different, shorter clips and average the predictions
When dealing with videos, the million dollar question is this: how do you integrate space and time?
Progress
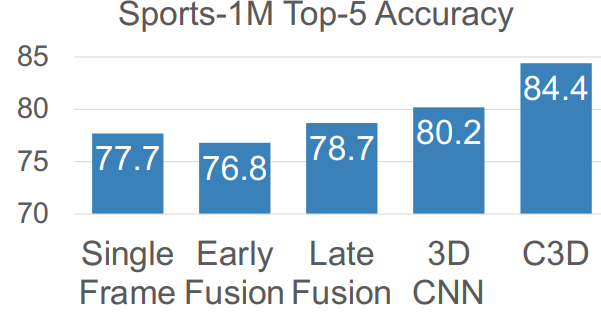
Single frame CNN
Here’s a primitive idea. Why don’t we run each frame through a CNN, get the predictions, and then average the responses?

Often, this is a very strong baseline! But we can do better!
Late fusion
Hmm, so maybe averages aren’t strong enough. Why don’t we take a feature embedding from each CNN, flatten them, and feed it through an MLP?
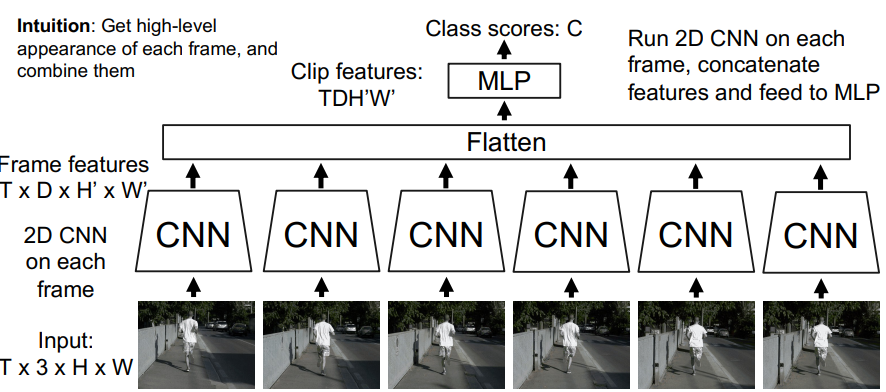
You might be able to get stronger results if you do some average pooling through space and time. In other words, why don’t you average all the “pixels” in the feature, and average those across time, so you just get a feature vector the size of the number of channels?
But there’s a pretty big problem here. By pooling and stuff, you lose track of low-level details, and these small details might be important for the main video.
Early Fusion
Why don’t we stack the video frames as if they are different channels?
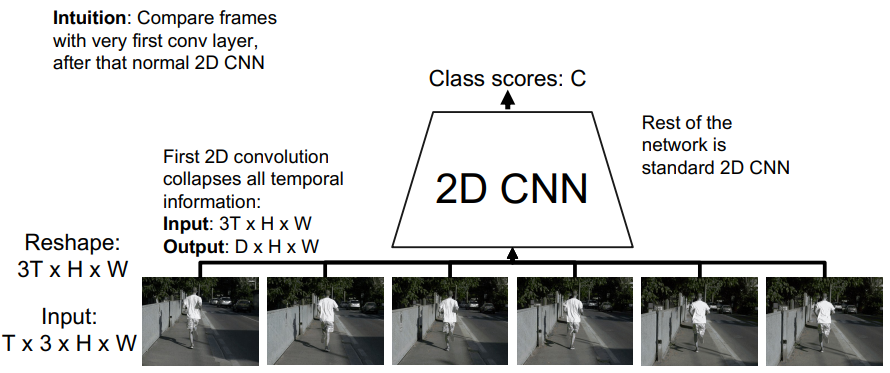
The problem here is that we lose the temporal aspect immediately, after one layer. So this might be too shallow
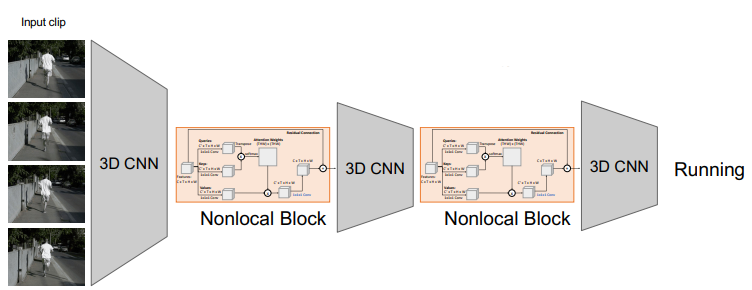
3D CNN
This is inspired by the problem we faced with early fusion. We collapsed the temporal aspect within one layer. Well, we take inspiration from 2D convolutions, which gradually stitched together the spatial components through multiple convolutions. Can we...do a 3D convolution?
Yes! So if you imagine having a 3D filter and moving it around in a box, you will get incrementally smaller boxes until you can flatten
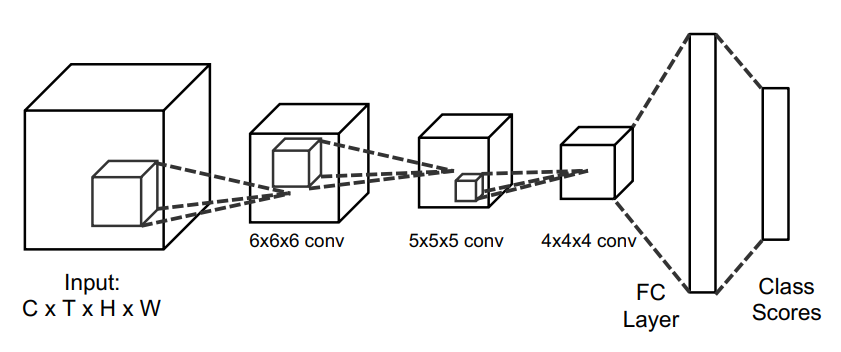
You can imagine a stack of these filter boxes acting on a stack of boxes, each representing a channel. The same dot product still applies, though.
Comparing receptive fields
Between early fusion, late fusion, and 3D convolutions, what is the most helpful? Well, you can make a comparison at how the receptive field grows. Ideally, we want it to grow slowly, so that the information can be condensed slowly without much rejection.
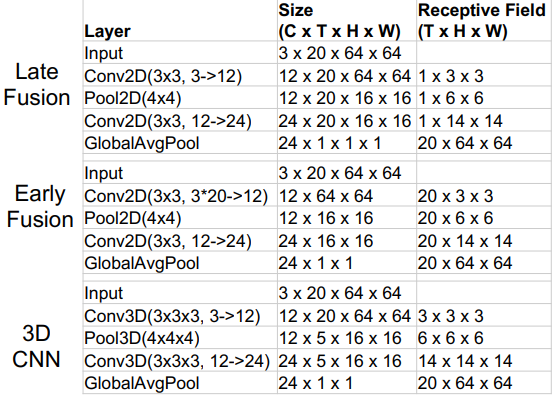
Again, early fusion collapses too quickly, because it treats the channels differently. Furthermore, because the channels are treated as distinct, early fusion is not robust to temporal shift! You need to learn separate filters if the actions are done in separate parts of the clip. Because 3D convs use the same filter in space and time, this invariance is brought back.
C3D
This is a classic model that many people use as a video feature extractor in pretrained form
I3D
Because 3D CNNs are very similar to 2D CNNs, one wonders if we can somehow adapt existing 2d CNNs for 3d. And you can! Just “inflate” the filters by one dimension
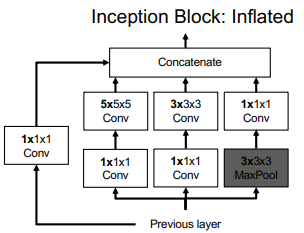
You can initialize the weights to a pretrained 2D CNN that you copy the weights over that inflated axis. This represents a good classifier if your video were just a constant image, but it still is a good start.
What and where pathways
Here’s the key insight. In our brains, we have separate stream of information for the “what” and the “where.” Can we separate out the spatial and the temporal stream of information too?
Optical flow
From a video, you can calculate the optical flow, which is basically a prediction of where the pixels will go. This is really helpful, because it abstracts the spatial aspects and essentially keeps only the motion

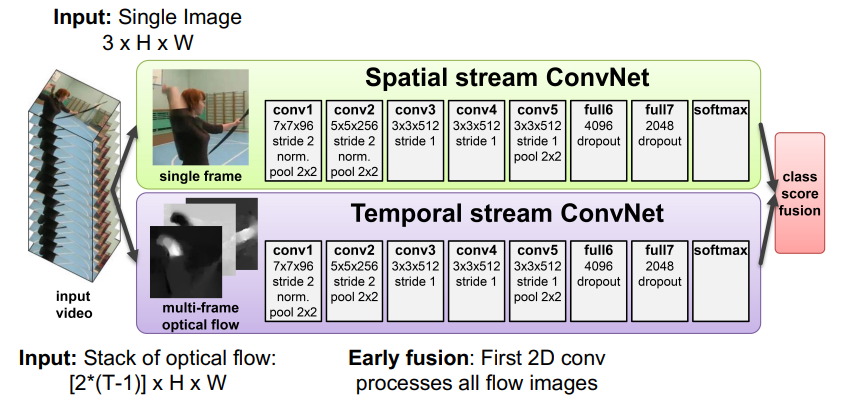
Two stream networks
here, we see an interesting architecture. You compute all optical flows, and you feed in one image. Then, you fuse everything at the end to get your classifier. The insight here is that we preserve the “where” through the optical flow and the “what” through the single image
Long-term temporal structures
So 3D CNNs are cool and all, but they can handle at maximum 5 seconds. What do we do with long-term dependencies?
Recurrences
We can extract short-term visual features with the 3d CNN, and then keep track of long-term features using a recurrent network like an LSTM. We can use a multi-layer RNN to help, if needed. You can keep the hidden representations in convolution operations too! No need to flatten. Just replace all matrix multiplications with 2D convolutions.
Attention
Transformers can be parallelized (the heads, etc) so this can help us with speeding things up
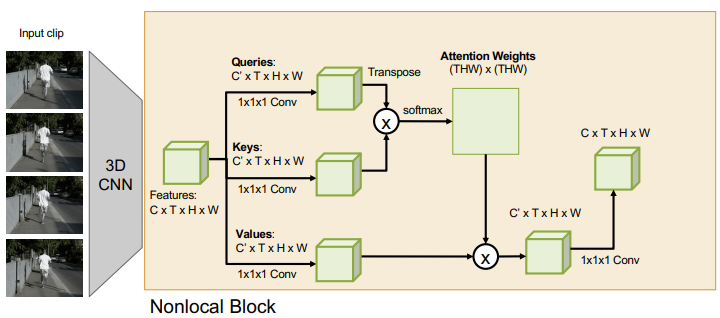
This is what a self-attention layer looks like. We can compose these with 3D CNN blocks, to look like something like
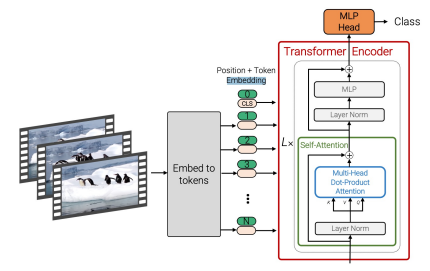
Vision transformers
These transformers will specify attention over space and time
Visualizing video models
Just like how we can perform gradient ascent on an image to do feature visualization, we can also visualize features in video. This gives you a video in return, which is super cool
Above and beyond
Temporal Action Localization
Given a long untrimmed video sequence, can you identify frames corresponding to different actions and classify them? You can do it similarly to Faster R-CNN. Propose time regions of interest, and then classify.
You can also extent this to Spatio-Temporal detection.
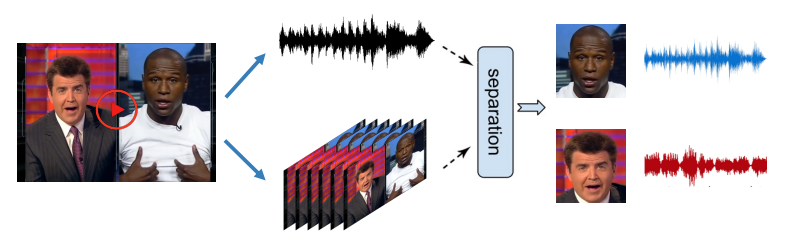
Visually-guided audio source sepratoin
You can use facial feature and other cues to separate streams of audio (coctail party but much better)
Audio as a preview mechanism
Sometimes, audio can be used as a way gauging attention. Interesting things sometimes come with more audio.
You can also learn audio-visual synchronization, or you can learn localization of sound