Segmentation
| Tags | CS 231N |
|---|
The tasks
- classificaiton: image → score
- semantic segmentaion: image → image of classes, where each pixel is assigned a class
- Object detection: image → bounding boxes around those images
- Instance segmentation: image → masks of objects
Semantic Segmentation
The goal is to take some image and classify each pixel. Of course, we can’t just take one pixel and run it through a network, because we need context. So, we extract a patch around each pixel, and then run a CNN over that patch. You assign the classification to the center of the patch.
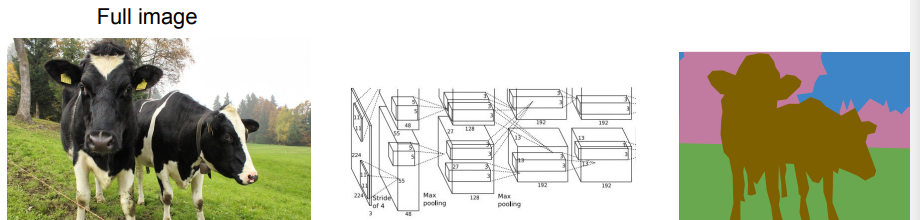
What’s wrong? Well, the problem is that it’s very computationally expensive. We need to do essentially forward passes.
Fully Convolutional segmentation
Here, we arrive at another idea. What if we ditched the whole classificaiton gig and produced the whole segmentation in one forward pass?
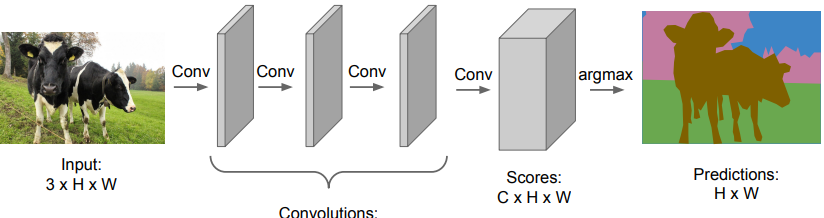
Hmm. So this seems to be a better idea, but the whole idea of convolutions is to make the computations cheaper by reducing the size. This isn’t happening, so the computations are still pretty heavy.
Downsampling and upsampling
We can do what is equivalent of a convolutional autoencoder, which allows you to work mostly in a lower resolution
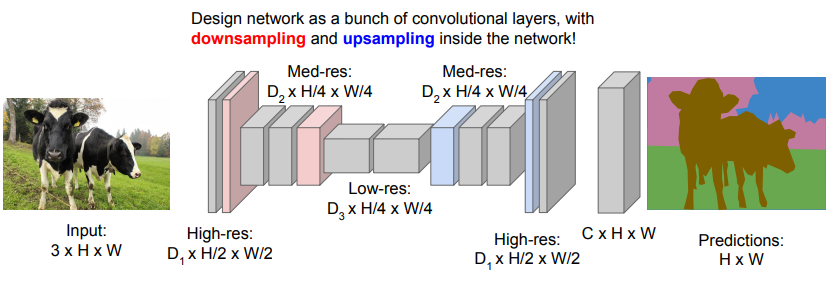
More details (in a paper)
Fully Convolutional Networks for Semantic Segmentation
Big idea: have a smaller CNN that gives a prediction for a small square of image. Then, “convolute” this model across a larger image. You essentially treat the output of this smaller CNN as the prediction of the center pixel’s type. Then, you assemble these things together into a segmentation map.
Because the sliding window will yield a lower dimensional output (and therefore too coarse of a segmentation), they use some intermediate features to help
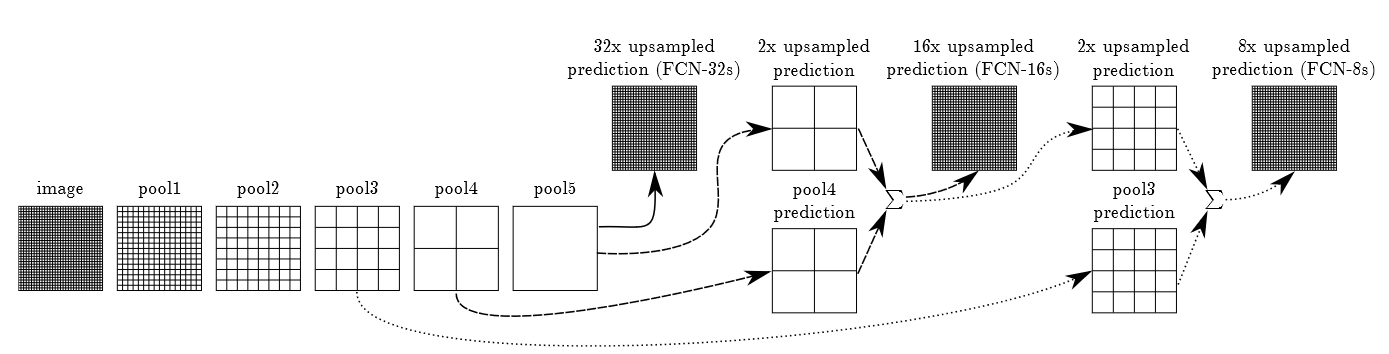

Object Detection
Single object detection
The goal here is to take an image and draw a bounding box around any meaningful object. At the most simple setup, you have an image with one object in it. Then, you can run it through a CNN that produces a class distribution and a box coordinate (x, y, w, h). The idea is that you are given a viewpoint and you are going to refine the viewpoint with this bounding box
With this setup, you can frame the object detection as a regression problem, with a L2 loss on the correct box and a softmax loss on the correct label
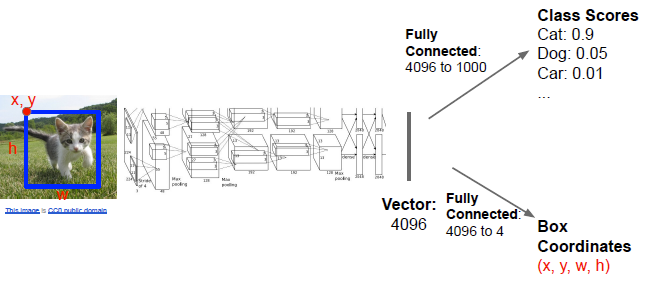
you train with a multitask loss (summation). We call the box coordinate generator a bounding box regression. You can also be more sophisticated and add rotation, or even 3d coordinates (see later section)
More on bounding box regression
It’s usually a relative change.
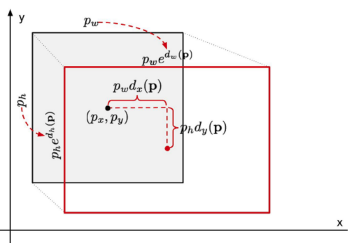
They scale the size in log-space, which means that , and you predict . You predict the relative center offset in non-log space, which means that , etc. This is just a little trick. Intuitively, you can think of the width and the height as being highly variable, while the location offset is not as highly variable.
Evaluating results
We use the IoU metric, which is the intersection over union. It’s best represented through a picture
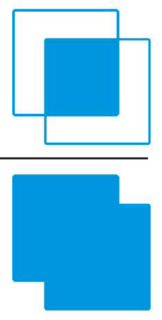
The insight here is that as the predicted box gets close to the ground truth, the numerator and denominator approach each other, which means that the ratio approaches 1. Anytime else, the union is always larger than the intersection, so the score is less than 1. It approaches 0 if there are no intersections.
For multiple bounding boxes, we can start to treat it as a classification problem again. A “match” is above a certain thrgraeshold of IoU, and then you can start plotting things like PR curves, etc.
Multiobject detection
but here’s the problem. In images, there may be more than one object that we care about! What if we have a bunch of ducks, or three dogs?
Simple idea: do a bunch of crops and run the simple object detector on it. Obvious problem: this is intractable, because you have to draw a bunch of boxes and often it’s up to random chance. In the next sections, we will look at some approaches that work much better
R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN)
There exists off-the-shelf, non-parameteric algorithms that will identify regions of interest in an image. For example, it might do KNN on an image and extract blobs of color larger than a certain size.
Now, this algorithm will propose a lot of boxes, and not all of them will be relevant. This is where your single object detector comes in!

You can scale each proposed box, and then run the single object detector on each one. You keep the boxes that have a class confidence higher than a certain value.
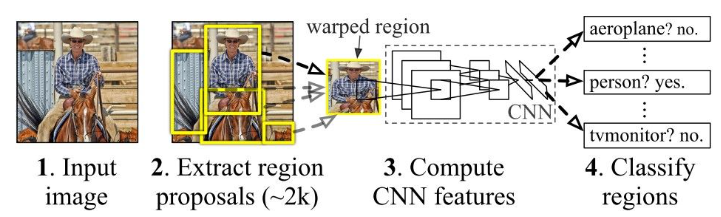
You use a pretrained convnet and then run a linear head on the features to get the bounding box and softmax
The problem is that you are doing a LOT of runs, and it is not efficient, especially because many of these share representations
Max suppresion
The problem is that the ROI can give you multiple boxes of the same instance, and they all can be pretty good.

To solve this, get groups of boxes that overlap by a specific threshold, say 70%. Sort the boxes by the confidence score (basically, how strong is the classifier?). Then, discard all but the highest confidence

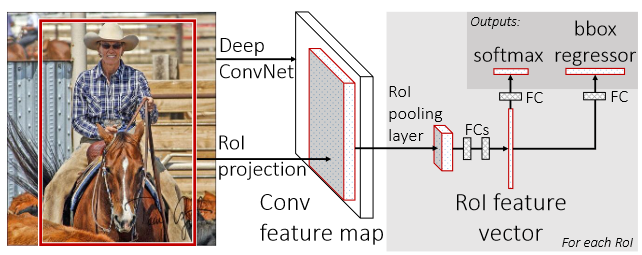
Fast R-CNN
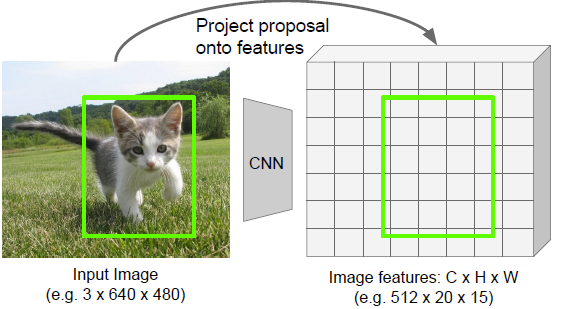
The intuition is that we can run a heavy CNN model to extract some features, and then project the regions of interest onto this feature space (because we keep the spatial relativity).
ROI projection
We can do this projection by literally shrinking the regions of interest, because the collapse of spatial size is uniform. But it might result in a projection that doesn’t exactly hit the grid line
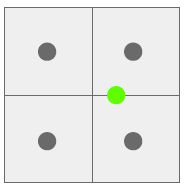
A naive solution is to snap it to the nearest grid. This is OK, but we realize that we might be changing the ROI by a non-trivial amount, because there is some spatial shrinking.
To solve this problem, you can essentially do spatial interpolation by drawing a grid of “pixels” relative to the projected ROI. Each “pixel” doesn’t fall on an actual pixel, but you can turn it into a convex combination of its four neighbors (bilinear interpolation)
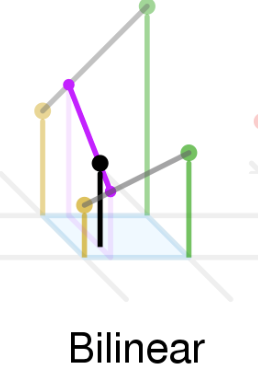
ROI pooling
Now, because the ROI are different sizes, you might need to do max-pool within each projected ROI to get it down to a uniform size. Then, you can run a lightweight CNN on the projected ROI in the feature space. This lightweight model will be responsible for the bounding box regression and classification.
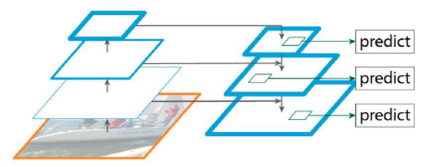
Pyramid structure
Here’s the key. You want the projected features from multiple feature layers. The smaller the layer, the greater the receptive field and the better the big picture. However, the larger the layer, the more details you have. So, you can have a pyramid of activations and combine the activations at each layer
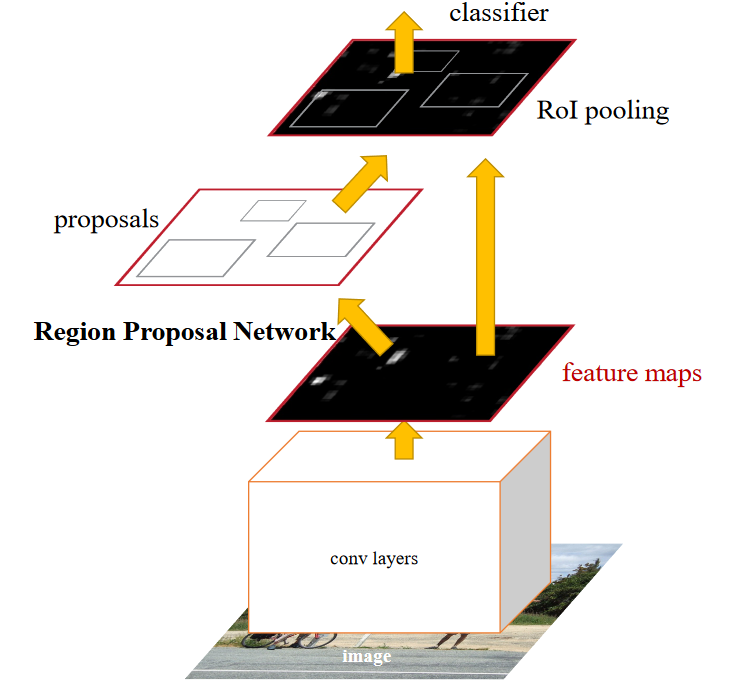
Faster R-CNN
Previously, the CNN was the bottleneck. Now, the region proposal algorithm is the bottleneck. Is it possible to propose regions using a CNN? Yes!!
You can run a heavy duty CNN to get a feature map, and then you can feed it through a region proposal network. Then, we run the fast R-CNN algorithm based on these region proposal locations.
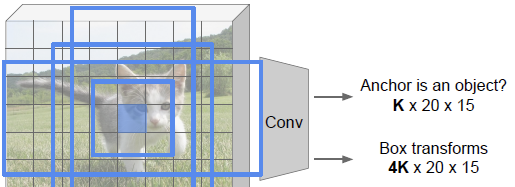
RPN
The region proposal network looks at each “pixel” in the feature maps. There are anchor boxes for each pixel in the map. We call the “pixel” an anchor point. The anchor boxes are different size and different aspect ratio rectangular boxes. These anchor boxes act as crops that you feed into another lightweight CNN.
For each of the anchor boxes in the whole grid of anchors, we get a score that represents the confidence that the anchor contains an object. It also outputs a bounding box of attention. This is NOT the bounding box for the actual object; it just represents where we want to pay attention, and the second stream (that R-CNN part) will make the actual bounding box.
You will sort the boxes by their confidence in the presence of an object, and take the top (where )
Putting things together
The top are given to the fast-RCNN to do the object detection and bounding box regression.
We optimize the whole model at once, which means that the gradient passes through the regional proposal network.
Looking only once
|YOLO (You Only Look Once)
So far, we’ve done pretty well with this dual stream proposal system. We propose a region of interest, and then we find the object inside the region of interest. While this works, we are left to wonder if we can do this all in one shot.
Here is the approach
- Divide the image into a grid, with anchor boxes in each grid cell
- for each grid element, regress to a 5-tuple that contains which is the proposed bounding box. In total, this is values. Add on for the class prediction, so each grid value you get a vector.
- You can stack this together to get a tensor. So this becomes just a convolutional problem! You start with a image and you convolute into a tensor.
- You pick the boxes with the highest confidence and assign it the proper category
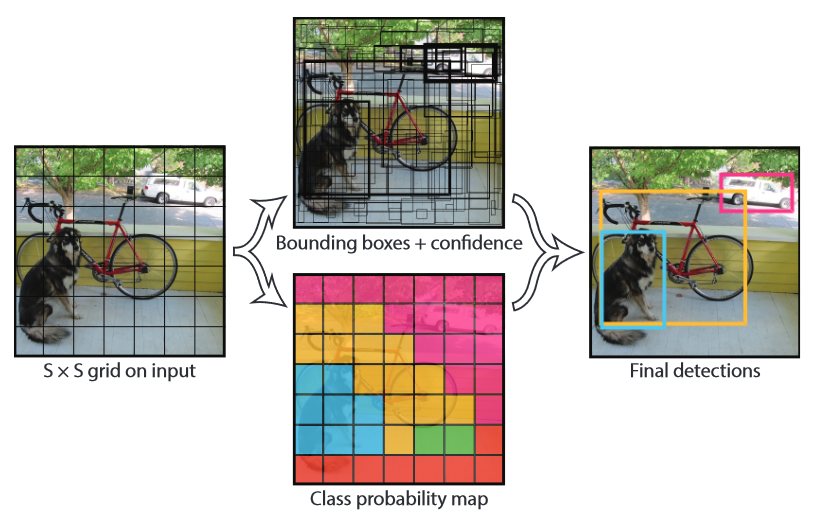
You train with a bounding box loss and a classifier loss, just like how you would train Faster R-CNN, etc.
Mask R-CNN
This allows us to do instance segmentation. Recall that we were able to do object segmentation using a primitive method. Instance segmentation is a little harder.
Fortunately, you can just use the existing R-CNN architecture and provide an additional output that predicts the mask around the object in question.
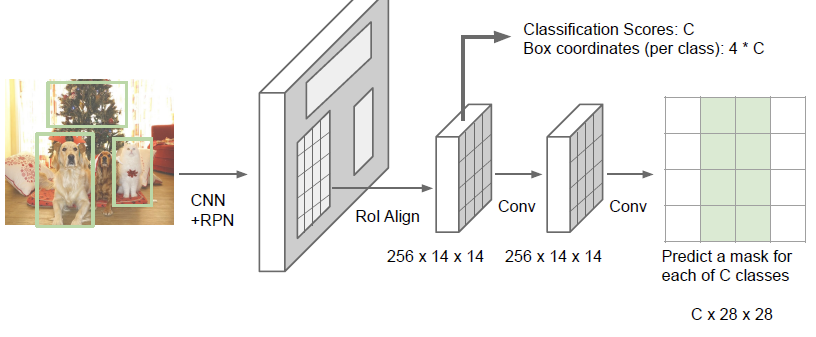
Basically, in addition to spitting out classification and box coordinates, you do further convolutions and at the end, you make a mask for each class in the region of interest. Then, you can select the mask that represents the class that the classification head predicted as the most likely.
This is still a supervised learning problem. You inject the gradient through the classification and box coordinates, as well as the mask step. The big upside to using this multi-head approach is that you can train most of your network using a simpler classification and box coordinate dataset, and then you can almost just finetune for the mask.
Above and beyond
Instead of classifying the bounding box, you can caption it. You can also do dense video captioning. More on this later, maybe.
With the recognition of objects, you can create scene graphs which represent objects and their relationships to each other
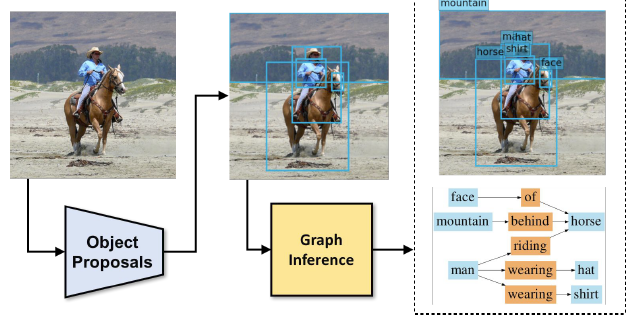
You can do this through a graph convolution and message passing, I think.
You can also make a simple modification to the 2d bounding box problem and add a 3d bounding box, with as the regression. However, this is part of the technology that self-driving cars rely on! They use models that recognize cars and their orientations.
You can take the 2d mask to another level and start predicting 3d meshes, which is super neat because now you can extract 3d models from pictures!