Low-level Image Processing
| Tags | CS 231N |
|---|
Optical Flow
Given two images, how do the pixels move horizontally and vertically?
Initial idea
Basically, you create a horizontal and a vertical optical flow map. You want to make sure that it is as smooth as possible, so you take the gradient of these maps (regularization). Then, here’s the key insight. Let be the function of intensity at point at time . Then, if you provide the right amount of and , the intensity should ideally stay as constant as possible, i.e.
Therefore, you can derive a function and you want to mimimize this.

Variants include using L1 norms, because sometimes it’s ok to have a pixel that is out of place, or a sharp edge.
This formulation can be iteratively derived without using deep learning, so it’s a classical method.
Flownet
Basically use a U-Net on concatenated frames. Stack the two frames together and have an up-convolution on the output to generate the optical flow. If you want to be more sophisticated, you can also extract features of the images themselves, and then compute a correlation layer which takes dot products in a small window to combine the two images together.
You can add a lot of bells and whistles, but unfortunately, it seems like this underperforms the classical approaches.
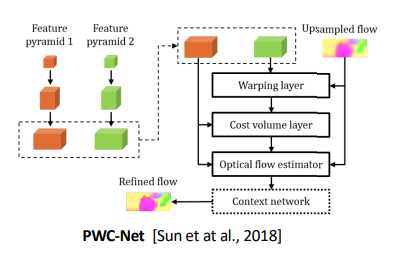
PWC-Net
Basically, iteratively refine based on different levels of feature extraction. For each level, you warp one of the features based on an estimated flow map. Then, you refine the flow and you keep on doing it.
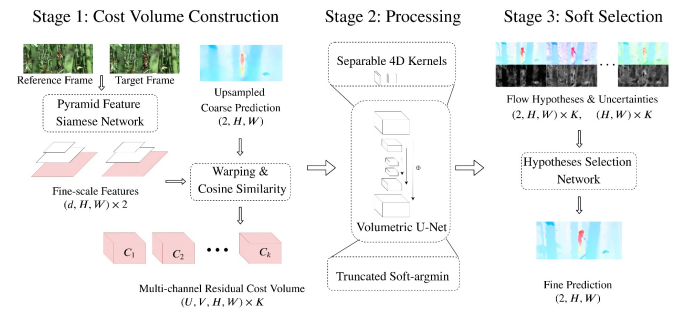
VCN
First, we extract features from both images. Then, we take the inner product across the images. So if we had a images, we would end up with a stack. For each pixel, we would have a heat map of where the pixels seem relevant. Then, we can use a 4D convolution and eventually use it to refine an optical flow
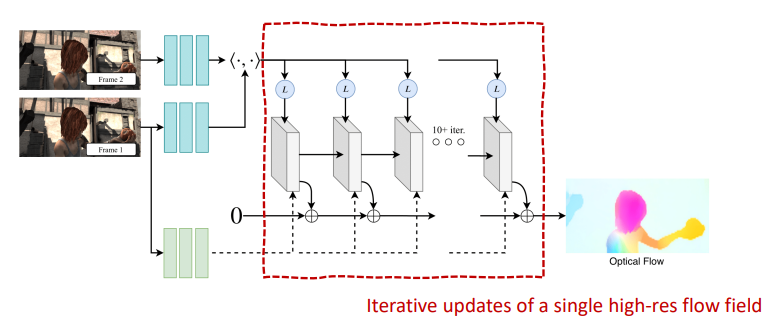
RAFT: Recurrent All-Pairs Field Transformss
RAFT takes inspiration from the iterative, classical approaches. Instead of refining a coarse map, we iteratively refine a single map from scratch.
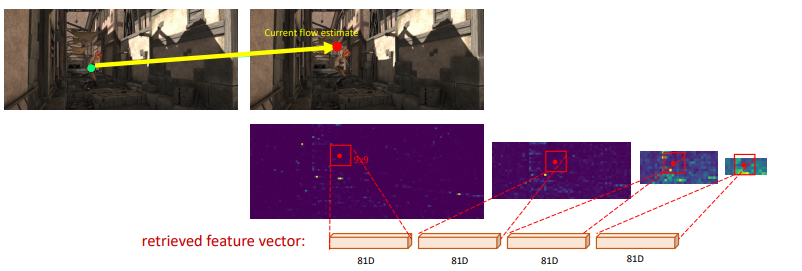
We extract features just like in VCN, by doing a dot product across all pixels to get a 4D tensor. We pool the last two dimensions, which gets us smaller and smaller heat maps but covering larger visual fields. Then, for each pixel, we take a box in the dot product space, and stack the windows across the different window sizes. This is what it looks like
Then, we run this through a GRU with a passthrough image that starts as the zero-image and slowly builds up features. We up sample using a weighted filter, which can help with detail selection
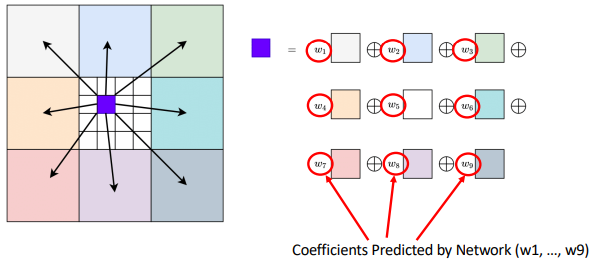
In training, we care about all outputs, but we decay the importance based on how far back the output is in the recurrent rollout
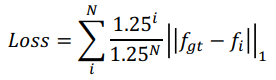
RAFT is more computationally lightweight because it doesn’t convolve in the 4d space, and rather takes 2d features.

Stereo
The problem: given two images, can we generate a depth map? Well, given the distance between cameras and a set point difference, we can actually easily calculate it!
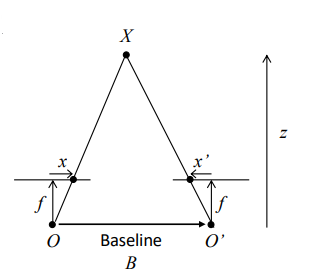
But how do we get the “shift”, essentially?
Naive approach
You might think that you can just slide the image onto each other horizontally until things “click”. Now, this might work, because there is just this horizontal shift. However, if there are repeating patterns, texture less surfaces, or occlusions, we run into trouble. Another problem is that sometimes there are shiny parts of the image that light up differently depending on how you look at it.
What they actually do
Depth cameras actually use dots of infared light, and because these dots get distorted in predictable ways, you can calculate depth pretty directly. However, it doesn’t work for shiny things or for things that are transparent.
Classical approach
Why don’t we match pixels on the entire scan line? In other words, why don’t we search for pixels on a horizontal line and this yields the depth?

RAFT-Stereo
Wait a second! If we care about horizontal translation, why don’t we formulate stereo vision as a horizontal optical flow problem? Indeed, we can easily do this. in fact, we can reduce the complexity. Instead of taking a window on the dot product space, we can just take a horizontal slit.
Localization and mapping
This is known as Visual SLAM (Simultaneous Localization and Mapping) and it is a hard problem. Given a video of a location, can we output a 3d point cloud map and a camera trajectory?

Classical approach
A 3d transformation can be projected deterministically onto a 2d plane, so if you are given the optical flow, you can solve for the 3d transformation.
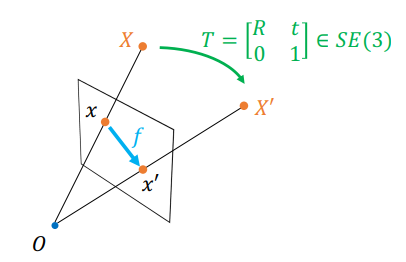
Unfortunately, this can have catastrophic failures, because inherently, you are trying to make more information from less information.
Deep Visual SLAM
Why don’t we regress video into 3d motion? This is a good idea, but it doesn’t seem to work quite well and classical methods usually work better.
DROID-SLAM
DROID stands for Differentiable Recurrent Optimization-Inspired Design, and it takes advantage of an iterative update approach, much like the RAFT project does.
To do this, they used dense bundle adjustment, which basically defines all images in the video as a node in the graph, and if two frames share pixels, they have an edge in the graph. Now, for every edge, you calculate an optical flow.
Now, you want depth maps and camera poses at every time step. For these, you can calculate the induced flow given these predictions. Now, you have a regression problem. Given the predicted flow from the images, and the induced flow calculated from predicted and , we can minimize. The diagram below is helpful
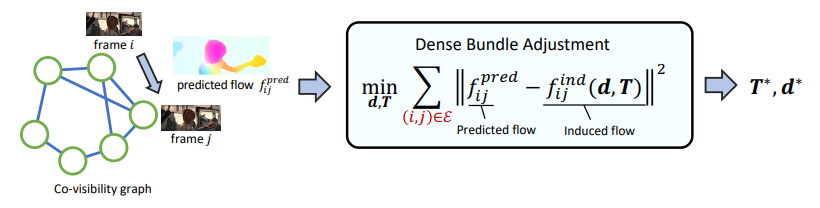
Naive Droid-Slam
So with our previous set-up, we can just plug-and-play using RAFT and an energy-minimizer
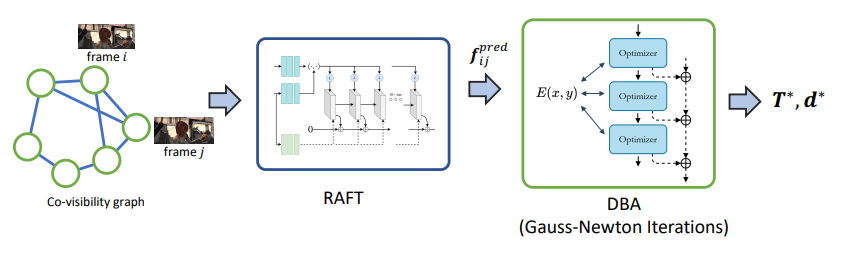
Unfortunately, this doesn’t work very well because they are distinct modules, and there may be outliers. To improve, we want there to be a closed feedback loop between RAFT and the optimizer. Right now, it’s only forward. Can the optimization influence RAFT?
The real deal
Well, why don’t we connect the two layers through a gradient?
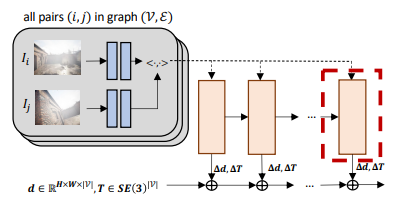
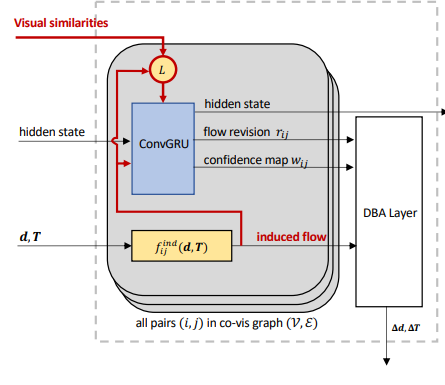
We can extract the flow through RAFT (gray section), but we also feed the induced flow into the GRU. The DBA layer is analytical and you can use a Taylor expansion to allow for differentiability. There’s more under the surface, but this is the macro perspective.
If you had stereo cameras, you just double the frames in the graph
and if you had depth camera, you can just use the sensor depth as a prior in your DBA layer. Again, because DBA is not trained, you don’t need to retrain the network to use the depth.